dolphin 高可用 registry
dolphin scheduler master的分布式高可用机制
原来这样就可以被叫做分布式高可用。
2024-05-13
跟着registry部分的代码走了一遍,大概清楚ds的高可用是个什么概念了。 官方文档说法实在太简单了,根本就看不出来具体的业务细节。
比较晚了没时间贴代码,大概写下流程。
主要看的是zookeeper版本的registry实现方法, 两个zk的主要特性需要了解:
- zk支持创建ephemral节点,在连接端client断开的时候,会自动被删除。 因此在实现分布式锁等场景,客户端应用挂了,锁也就自然释放了。在高可用场景,客户端应用挂了,zk也能快速识别到。
- zk支持订阅具体路径。在某个路径添加或是删除的时候,会主动发送消息给订阅客户端。
dolphin scheduler的ha流程,快速手写。
- master server启动的时候会在zk里创建master的临时节点,具体的参数就是server的heartbeat内容。
- 同类型的机器节点会使用相同的前缀,比如/nodes/master. 因此直接查看这个前缀的children,就能够获得整个ds集群里的master机器。
- master server启动的时候会注册监听父类路径,比如/nodes/master,这样有新机器增加和删除的时候,master能够收到zk发送的event。
- master server作为zk客户端还订阅了connection event,这个是zk client客户端的事件,在客户端断开链接的时候,master server自动根据内部逻辑进行处理。waiting策略会重试连接,stop策略会直接关闭。
- master server会不停的发送心跳,心跳内容就是机器的cpu内存和启动时间等信息,不断更新注册的临时节点。 (个人觉得这种方式,有助于解决客户端脑裂问题。比如在gc等环节导致pod失去响应而丢失临时节点的场景里,在pod恢复后会重新创建临时节点,加入集群里)
- master server在接受到机器变更信息后,会自动更新本地所有机器的列表。机器按照启动时间排序,当前机器因此会有个次序index。
- 等待分发的任务都持久化在数据库里,master根据自己的slot去数据库里找每个批量的命令进行处理,各管各的slot batch。 具体方式是通过id与集群总数取余,然后得到当前slot的batch。
- 通过这种方式,每次新增加机器和减少机器,都会触发slot的变更,每次都去处理新的任务批次 (这里容易存在问题,每个机器都变更了slot,岂不是导致任务处理容易出现混乱?能够保证去获取命令的所有master机器,都在同一时间更新了slot了吗?除非用分布式锁去锁住每批次获取的命令,并且在获取后自动update数据?)
- 识别到有其他机器关闭后,当前master会去抢锁,然后处理这台被关闭机器的运行中的任务。具体是通过筛选数据库里的命令记录列表,按照机器,时间和状态筛选, 然后update server为空,再发出新的failover command。这里面的细节还挺多,筛选的时候还要判断是否原来的机器已经重启了。 这就是ds的failover机制。
梳理清楚流程后就发现很简单了, 看起来就是master注册zk临时节点, 根据总的节点index分配slot, 然后根据slot去查询待下发的命令。 master挂了的话,其他master会接收到zk的注册事件,尝试处理原来master的command来做failover。
这竟然可以被叫做分布式高可用。
简化版的话,有个其他思路来实现: 每个master都搞成pod无状态, 批量到数据库里获取任务,尝试获取redisson分布式锁,获取到就自己执行,应该也可以? 如果某个master已经挂了,那锁也就中断了,这时候被其他master获取到就自动接管过去。
master实现高可用的一个重点,还是每个任务的进程都在数据库里留下记录,这样master的任务都可以进行跟踪记录。
看到的两个bug
- fail over获取lock的时候,并没有使用try lock快速返回的写法。如果其他lock已经被使用,其实会被阻塞。
- priority queue在使用iterator遍历的时候并不会维持顺序。 后台有线程定时更新server map和slot index,用iterator实现的话每次的排序的结果可能不一样。
参考文档
官方文档高可用部分描述
https://dolphinscheduler.apache.org/zh-cn/docs/3.2.1/architecture/design
- 去中心化高可用
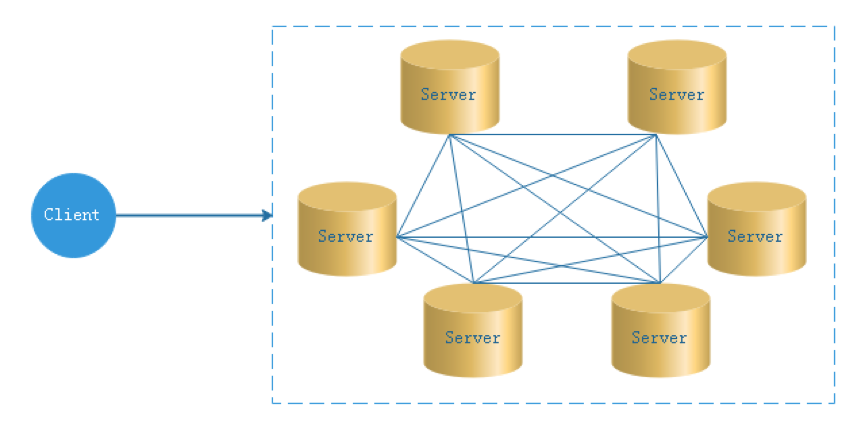
在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的,全球互联网就是一个典型的去中心化的分布式系统,联网的任意节点设备down机,都只会影响很小范围的功能。 去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠性,则大大增加了上述功能的实现难度。 实际上,真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。 DolphinScheduler的去中心化是Master/Worker注册心跳到Zookeeper中,Master基于slot处理各自的Command,通过selector分发任务给worker,实现Master集群和Worker集群无中心。
- 容错设计
服务容错设计依赖于ZooKeeper的Watcher机制,实现原理如图:
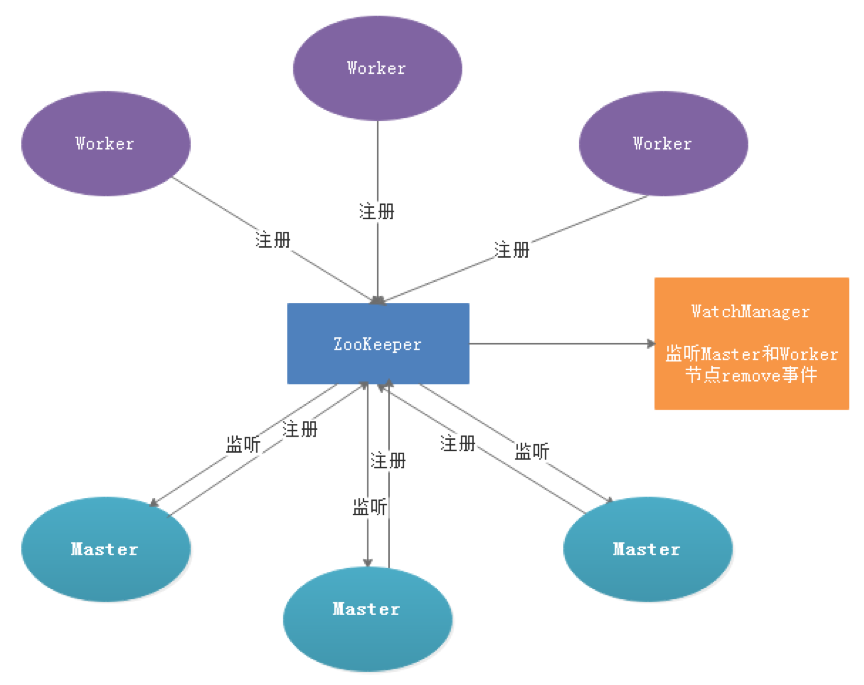
其中Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。 Master容错流程:
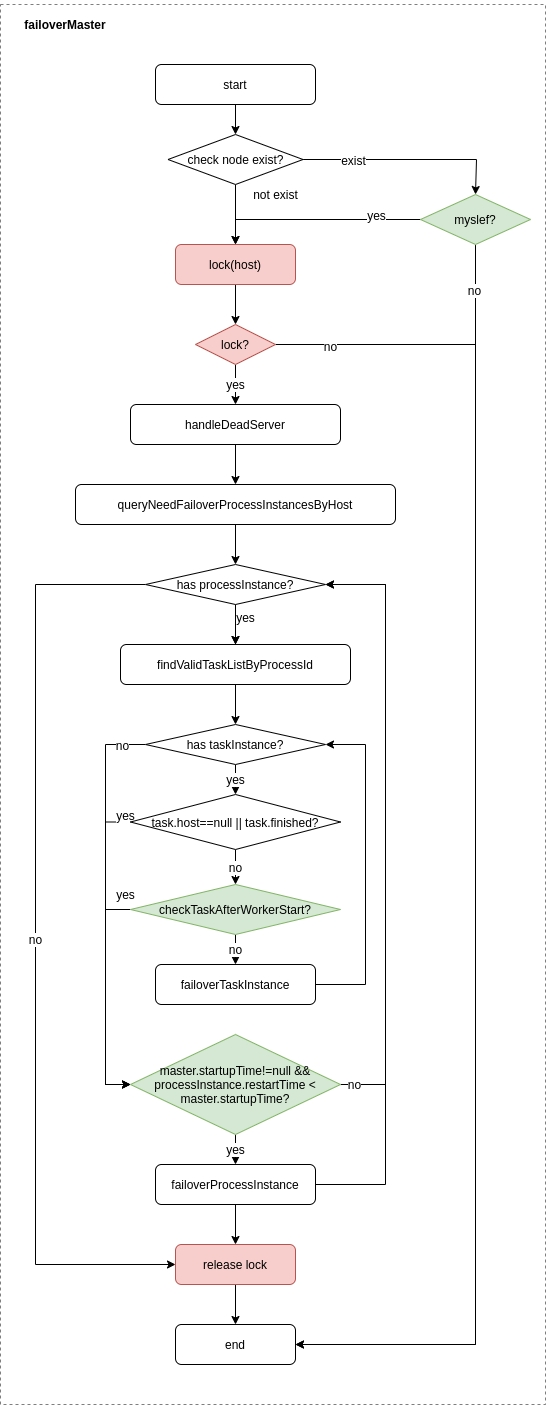
容错范围:从host的维度来看,Master的容错范围包括:自身host+注册中心上不存在的节点host,容错的整个过程会加锁;
容错内容:Master的容错内容包括:容错工作流实例和任务实例,在容错前会比较实例的开始时间和服务节点的启动时间,在服务启动时间之后的则跳过容错;
容错后处理:ZooKeeper Master容错完成之后则重新由DolphinScheduler中Scheduler线程调度,遍历 DAG 找到”正在运行”和“提交成功”的任务,对”正在运行”的任务监控其任务实例的状态,对”提交成功”的任务需要判断Task Queue中是否已经存在,如果存在则同样监控任务实例的状态,如果不存在则重新提交任务实例。
基于 DolphinScheduler 构建分布式大数据调度平台实践
看完代码后,看到这篇文章写得还是不错的,有不少前因后果讨论,比官方文档的一张图好多了。
https://open.oceanbase.com/blog/5204512768
在最初的架构设计中,MasterSever 和 WorkerSever 完全隔离,WorkerSever 拿到任务之后,把任务更新到数据库里面,导致 WorkerSever 对于数据库造成的压力非常大。比如联通把省公司的数据都汇总到数据中心,有一百多台的 WorkerSever 节点,WorkerSever 又做了数据库的连接池,数据库的压力会非常大。WorkerSever 负责执行各种工作流,这也是调度系统经常会用到的,我们希望工作流和工作流之间是有设计方法的,比如数仓按照数仓的分层原则,一层一层之间十分地清晰。
我们有一个依赖类型,这个依赖可以跨项目、跨工作流去依赖其他不同频度的任务,比如说一个天任务,依赖一个小时的任务,这里有一个依赖节点就可以了。整体上有一个注册中心,WorkerSever 都可以接受注册,WorkerSever 挂了,MasterSever 恢复,MasterSever 挂了,有其他的 MasterSever 监听到,其他的 MasterSever 接受它的工作流,进行故障 MasterSever 恢复。
MasterSever 1.0 时代的设计是无中心化的,遇到的问题是如何让 MasterSever 同时工作。我们先设计了一个简单的方式,先抢锁,然后去工作,跟踪的时候发现 Zookeeper 去充当锁,或是 MasterSever 去充当锁,抢锁的时间需要 50 -60 ms,非常慢。于是,我们又做了设计上的优化,首先是抢锁,抢到锁之后,把整个工作流界面做成一个图,然后去构建工作流,最终再把每个运行的任务形成任务实例。这是 1.0 时代的设计,后来发现性能比较低。
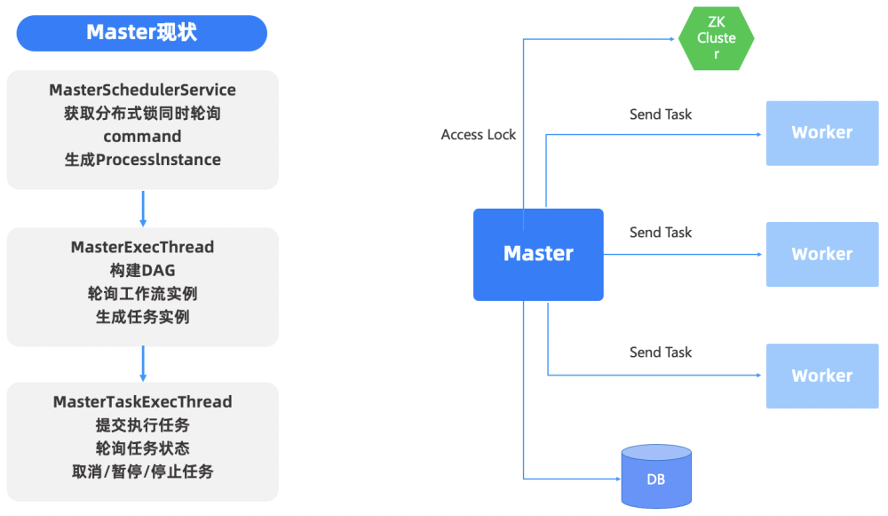
去分布式锁设计—1.X原先设计
在 Dolphinscheduler 2.0 时开始找分布式锁,我们根据 MasterSever 的算法,支持多种拓展,来找到它们的槽位。先去做分片,注册 MasterSever 会生成一个分片编号,Command 是执行的工作流,在去分布式锁的时候进行了这样的一个设计,根据槽位查询数据库,然后会生产工作流的实例,交给 Worker 执行,根据分片的槽位去计算。这就是去分布式锁设计。
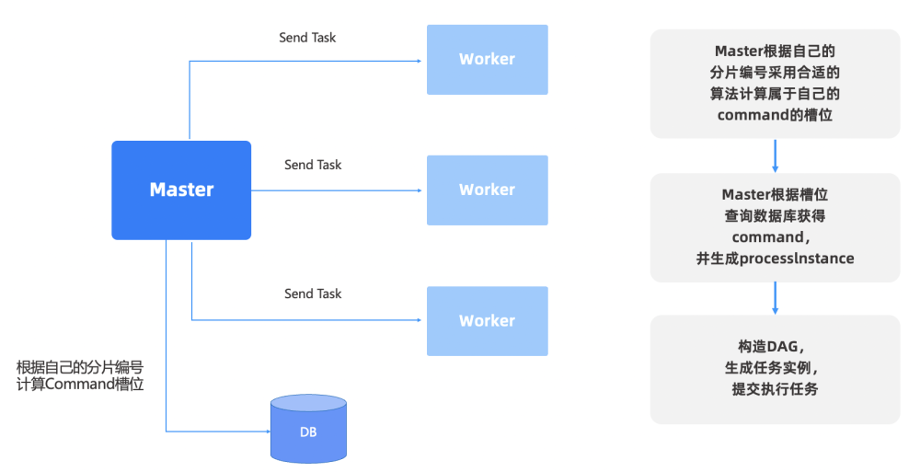
去分布式锁设计—新版本设计