kyuubi 数据治理
spark 自身的thrift server据说不支持用户资源隔离(个人没有测试研究), 国内网易开源的 apache kyuubi 提供了租户隔离和资源隔离的解决方法. 看了下源码仓库, 还支持了ranger鉴权, spark血缘解析, 一套数据治理方案直接打包了. 如果kyuubi确实稳定可用, 可以省去很多使用spark的数据治理的麻烦.
直接使用spark, 如果直接读取hive metastore, 不配置与hive server2交互, 会发现ranger策略完全不生效, 毕竟hive ranger plugin原理上就是从hive server2触发的ranger权限请求. 同时spark的血缘也很麻烦, 不像 hive 可以通过 atlas hive血缘插件直接解析.
看了下kyuubi的数据治理插件代码, 都是解析spark执行计划(logical plan)的策略, 从里面解析出执行的血缘关系, 抽取出库表调用ranger api进行鉴权. 都是琐碎而细节的代码, 这些开发人员真有耐心, 也很有水平.
看起来在使用spark sql的地方, 都可以直接切换为kyuubi进行使用, 只是不知道实际生产环境里的稳定性/可用性/拓展性如何.
kyuubi 官方介绍
https://kyuubi.readthedocs.io/en/v1.6.0-incubating/index.html
一句话介绍, kyuubi为spark提供了jdbc接口和多租户体系.
Kyuubi™ is a unified multi-tenant JDBC interface for large-scale data processing and analytics, built on top of Apache Spark™.
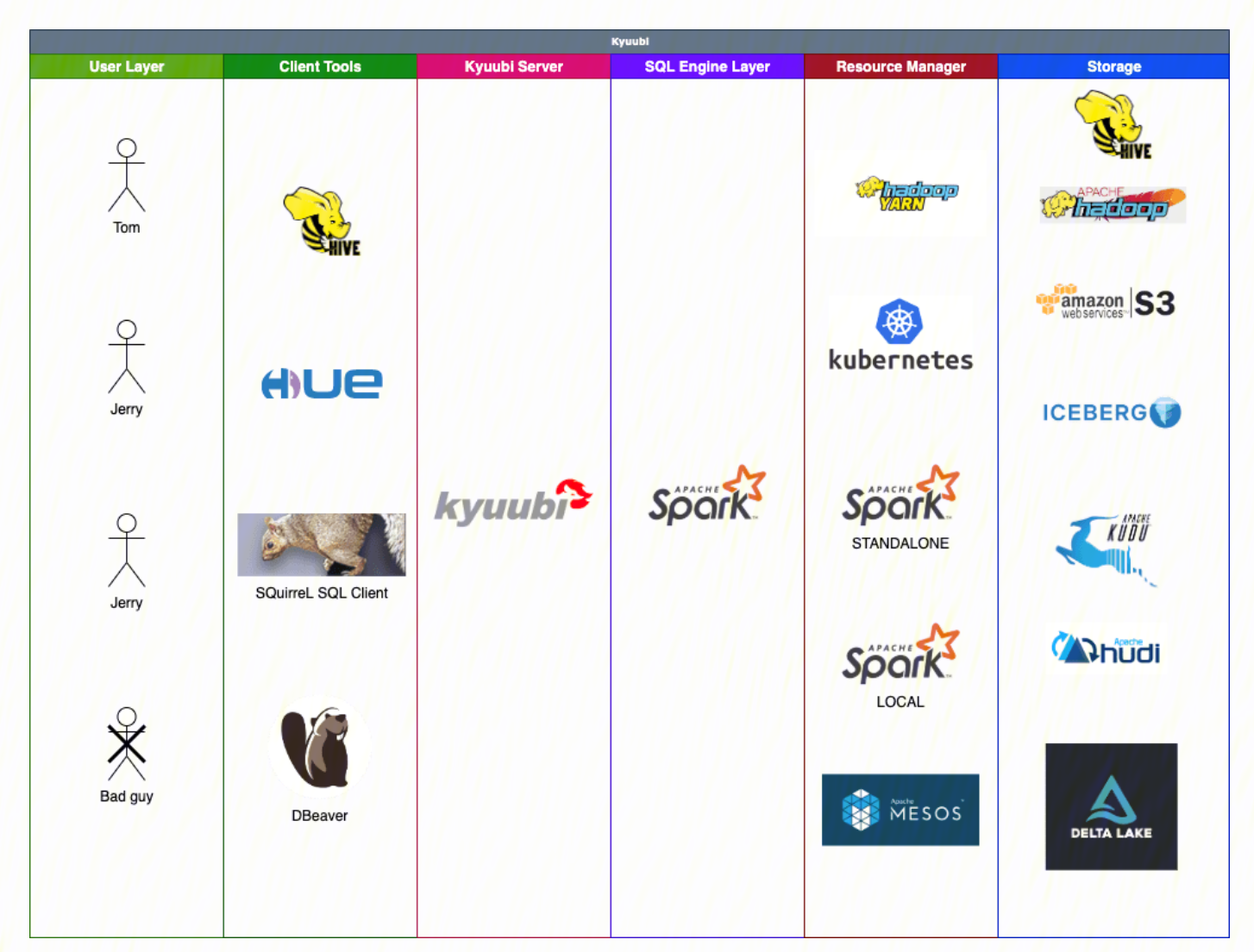
kyuubi的关键特性, 就是支持多租户体系, 一个用户一个spark应用. 有了用户信息和资源隔离, 进而支持权限管控, 不管是yarn还是k8s的namespace.
Kyuubi supports the end-to-end multi-tenancy, and this is why we want to create this project despite that the Spark Thrift JDBC/ODBC server already exists.
- Supports multi-client concurrency and authentication
- Supports one Spark application per account(SPA).
- Supports QUEUE/NAMESPACE Access Control Lists (ACL)
- Supports metadata & data Access Control Lists
Users who have valid accounts could use all kinds of client tools, e.g. Hive Beeline, HUE, DBeaver, SQuirreL SQL Client, etc, to operate with Kyuubi server concurrently.
The SPA policy makes sure 1) a user account can only get computing resource with managed ACLs, e.g. Queue Access Control Lists, from cluster managers, e.g. Apache Hadoop YARN, Kubernetes (K8s) to create the Spark application; 2) a user account can only access data and metadata from a storage system, e.g. Apache Hadoop HDFS, with permissions.
可以四处提交, 兼容各种spark集群
Kyuubi can submit Spark applications to all supported cluster managers, including YARN, Mesos, Kubernetes, Standalone, and local.
kyuubi 高可用, 后台常驻spark集群, 可以支持快速响应实时查询.
- Concurrent execution: multiple Spark applications work together
- Quick response: long-running Spark applications without startup cost
- Optimal execution plan: fully supports Spark SQL Catalyst Optimizer,
kyuubi 介绍与livy对比
搜了几个文档, 说的都是spark thriftserver不可靠没有资源隔离, 接下来说到spark livy, 支持用户资源隔离, 但是只支持http请求, 不支持thrift或者jdbc, 启动需要等待后端就绪速度慢, 还有各种限制, 一致推荐的都是kyuubi.
腾讯云Kyuubi简介
https://www.tencentcloud.com/zh/document/product/1026/46462?lang=zh&pg=
Apache Kyuubi (Incubating)是一个 Thrift JDBC/ODBC 服务,目前对接了 Apache Spark 计算框架(正在对接Apache Flink计算框架以及Trino),支持多租户和分布式等特性,可以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。
hue连接kyuubi
https://www.tencentcloud.com/zh/document/product/1026/46461
使用 EMR Hue 整合 Apache Kyuubi 提升 Spark SQL 开发效率
当在 Hue 中使用 Spark SQL 进行任务开发时,Hue 中 Spark 默认配置是 HiveServer2,执行的是 MapReduce 任务,效率比较低。如果在 Hue 中配置 Livy 来进行 Spark SQL 作业开发,Spark SQL 提交到 Livy 执行的时候,一次只能提交一条语句,并且会出现 SQL 语句不能自动提示以及无法返回任务错误日志等问题,这极大地影响了客户的使用体验以及日常开发效率。在通过相关的产品调研之后,发现 Apache Kyuubi 能较好的解决这一痛点。
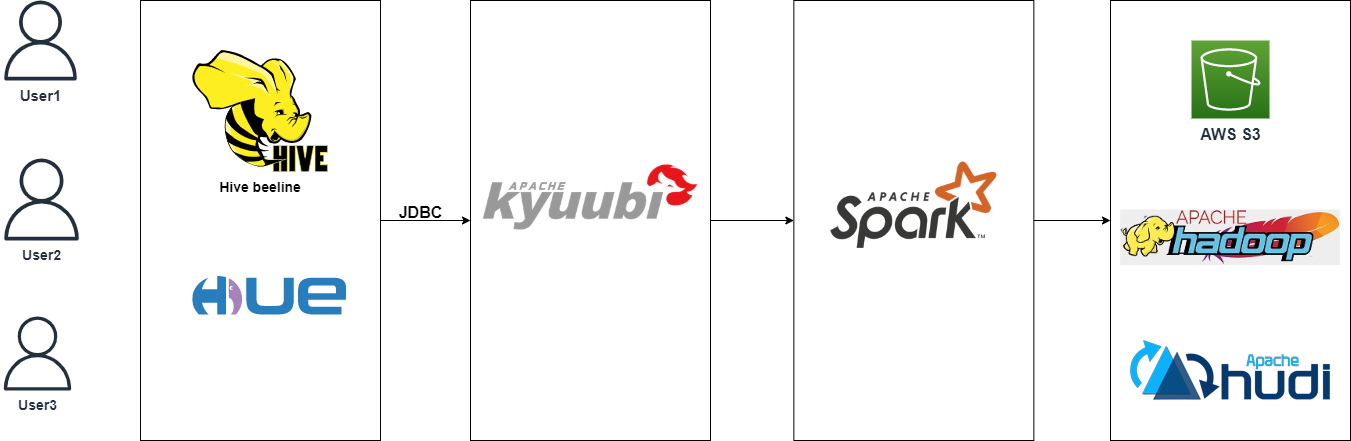
Apache Kyuubi 是一个统一的多租户 JDBC 接口服务,用于大规模数据处理和分析。它扩展了 Spark Thrift Server 在企业应用中的场景,其中最重要的是多租户支持。Kyuubi 实现了 Hive Service RPC 模块,它提供了与 HiveServer2 和 Spark Thrift Server 相同的数据访问方式。通过 Hue 和 Kyuubi 整合,用户通过 Hue 可以直接进行 Spark SQL 查询计算和数据处理。一个典型的数据交互方式如下图:
kyuubi vs hive on spark
https://kyuubi.readthedocs.io/en/v1.6.0-incubating/overview/kyuubi_vs_hive.html

其他一些可参考的kyuubi博客
基于kyuubi+spark3 加速hive批计算任务
https://blog.csdn.net/a80090023/article/details/121681157
这篇博客讲了如何讲平台从hive引擎切换到spark引擎,有不少思路可以学习. 比如对hive sql使用spark sql explain, 能够成功解析的就直接无缝切换引擎, 无法解析的仍然通过hive执行, 并提醒用户进行语法修改.