hive 架构
ranger/airflow这类业务辅助型组件的源码还是比较容易看完的, 目标也明确, hive/spark这种正经大数据组件就不是一回事了. 开源社区多少人耕耘了多少年写出来的东西, 代码量和复杂度就不是一个层级的. 日常crud的业务代码, 在这种大规模组件的代码面前, 真是玩具. 多少做大数据治理的, 困于日常搬砖, 就没看过这些组件的源码, 只能滥竽充数的搬砖. 但是打工人也得衡量下, 是否真的有那么多奢侈的时间去把这些看完?
看一些架构图再到处看看, 比较容易理解.
hive design
https://cwiki.apache.org/confluence/display/hive/design
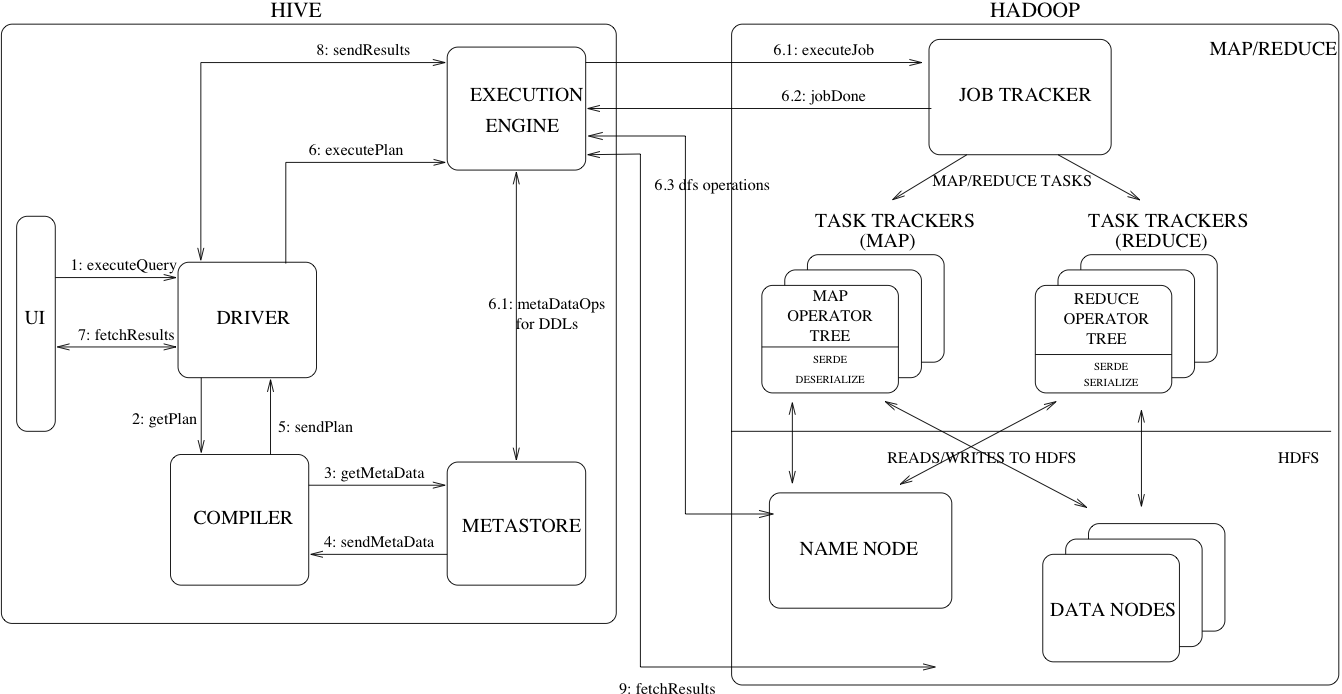
A Deep Dive into Apache Hive Architecture: From Data Storage to Data Analysis with SQL-like Hive Query Language
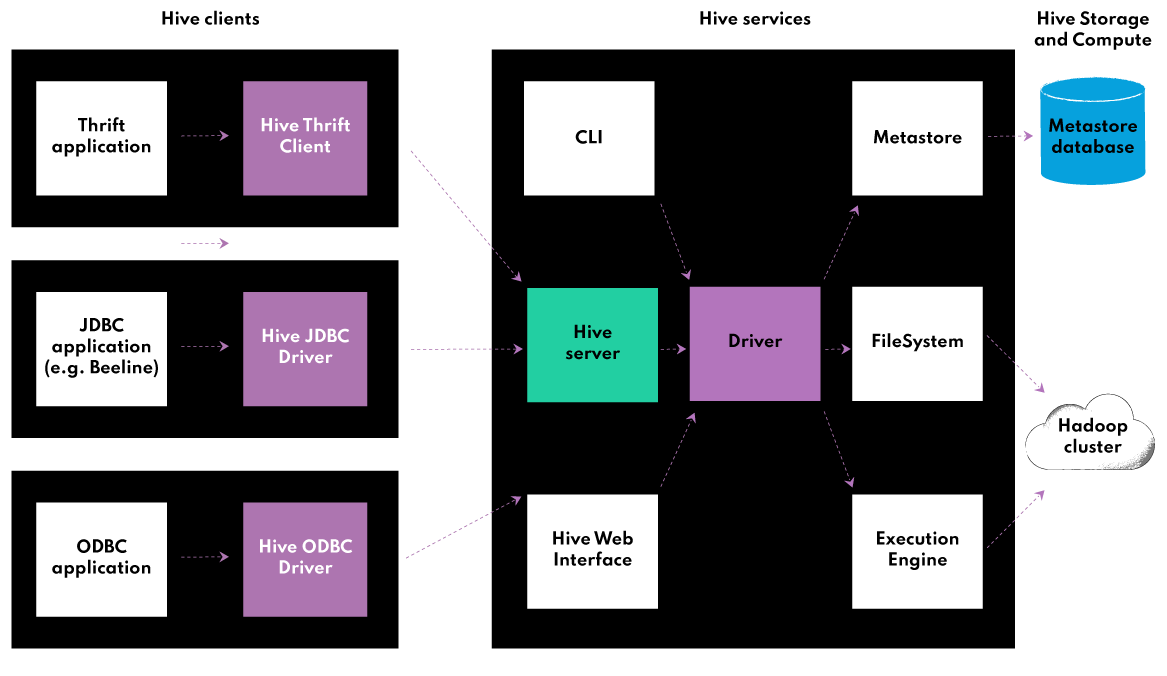
https://nexocode.com/blog/posts/what-is-apache-hive/#key-use-cases-for-hive
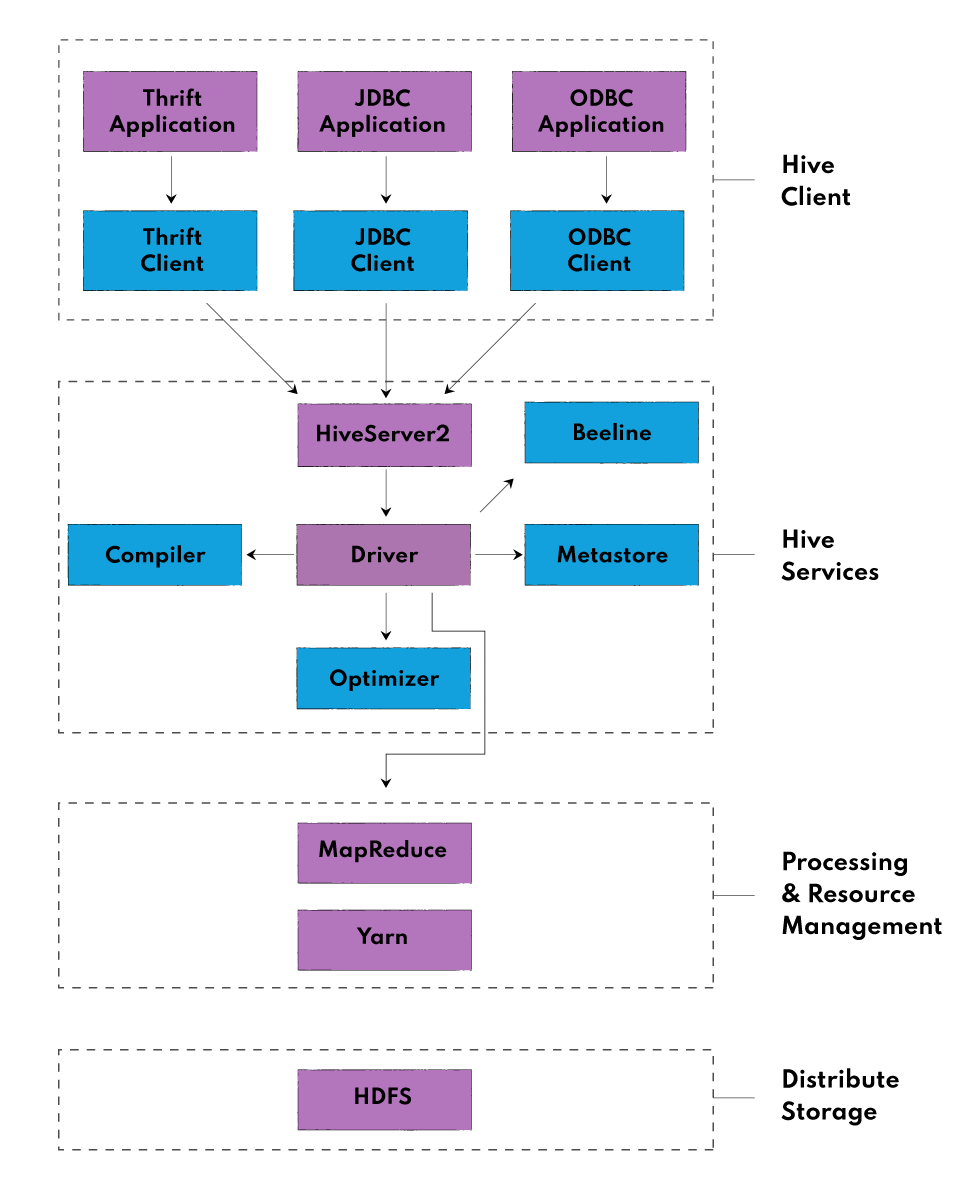
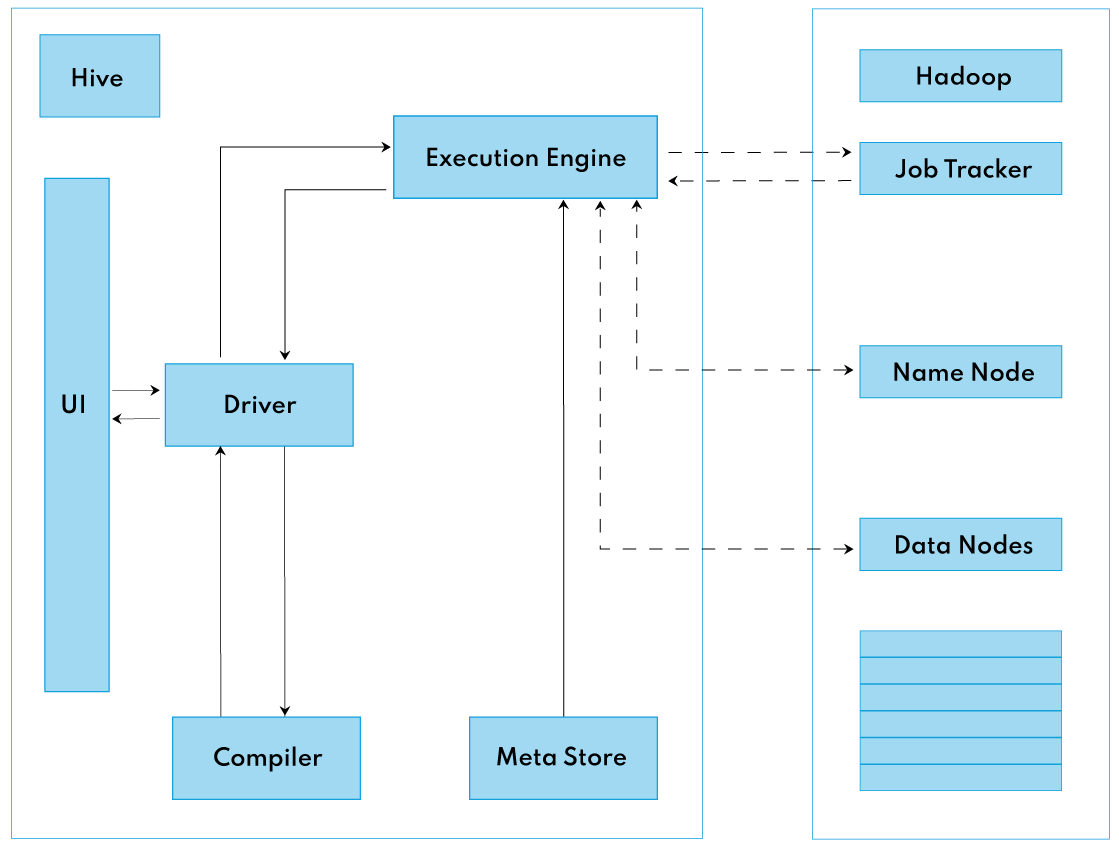
created at 2023-09-03