阿里开源大数据平台3.0技术解读摘录
看起来阿里的技术实力还是强, 而且是成体系的往前推进的感觉. 为了做数据湖仓, 直接做了个新的实时数据格式, 在iceberg/hudi这些主流之外又整了个全新的paimon数据湖格式, 与flink深度结合, 还是apache开源. 难怪最近在看一些字节等公司的技术分享时, 开始看到这个没听过的数据格式名词. 为了做serverless, 把很多组件一个个都serverless化处理, 而且是成体系的往前推进, 看起来工作量也是不小.
阿里巴巴-云栖2023-开源大数据平台3.0技术解读摘录
https://mp.weixin.qq.com/s/iEAl4qk2pkabCi-vfOBRyA
实时湖仓 flink + paimon
新一代的数据分析架构——流式湖仓, 将传统的 Hadoop 技术向新一代的湖仓分析 Lakehouse 架构进行演进。
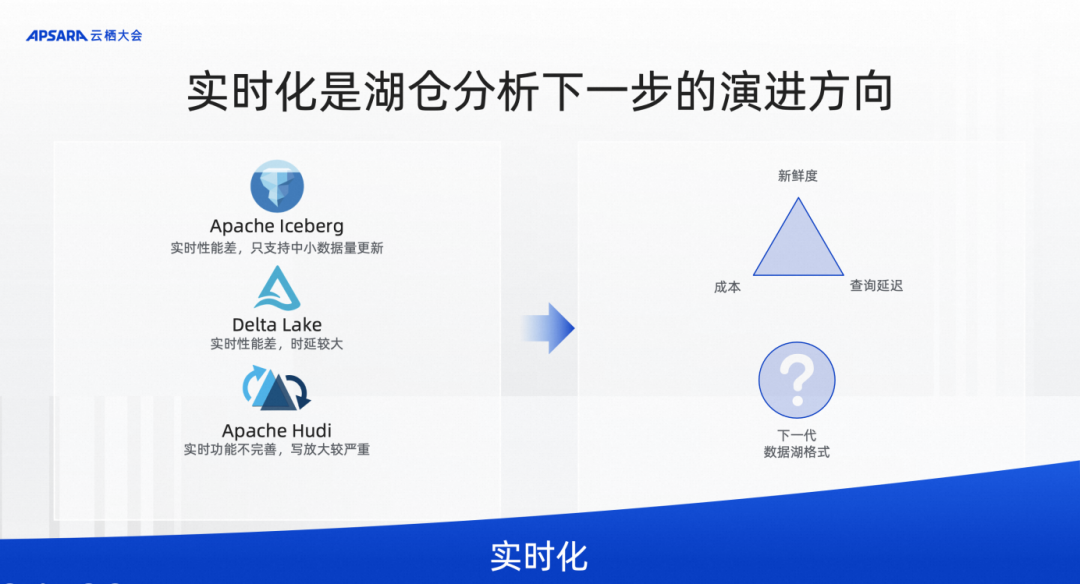
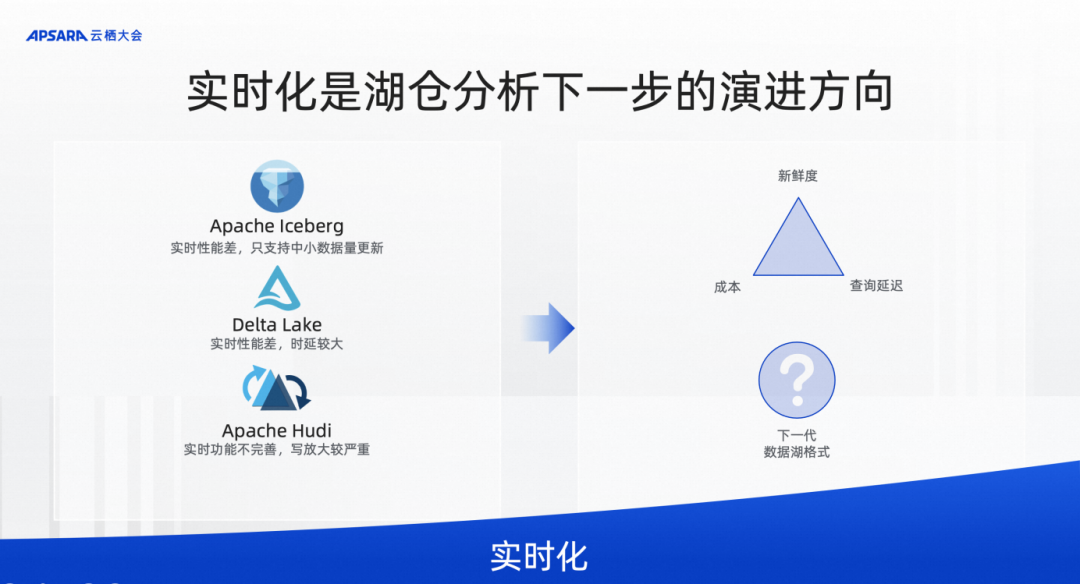
大家可以看到现在数据湖存储格式主要是 Iceberg、Delta、Hudi 三剑客来构建的,不同的用户和厂商会选择不同的数据库格式。但是 Iceberg 和 Delta 是面向批处理而设计的数据湖格式,与批处理的计算引擎配合更多一些,在 Lakehouse 上实现批处理,甚至可能是比较大力度的微批处理,通过 merge 来更新。这个架构无法彻底实现实时化,或者在实时化的力度上也做不到特别细粒度,比如分钟级的粒度甚至十分钟级的粒度都是非常困难的。
去年我们在 Flink 社区进行了技术探索,在 Flink 社区里启动了一个新的子项目叫 Flink Table Store,其目的是尝试看 PMF(市场的接受程度)。通过 Flink Table Store,发现设计一款真正面向实时更新的数据湖格式还是非常有必要的,尤其是跟 Flink 这种实时流式计算引擎配合,完全能在数据湖 Lakehouse 架构上,实现实时化数据链路。
为了让这个项目有更好的发展,我们今年决定把这个项目从 Flink 社区中独立出来,作为一个独立的 Apache 基金会项目去孵化,使其有一个更大的发展空间,命名为 Apache Paimon。
Paimon 是真正为实时更新而设计的数据湖格式,并且是完全开放的,不仅支持 Flink,也会支持 Spark、Presto、Trino、StarRocks 等主流计算引擎。
serverless 大数据组件

计算型选择了用户呼声最高的 Spark 和 StarRocks,这两款引擎推出了 EMR Serverless StarRocks 和即将发布的 EMR Serverless Spark 两款计算型 Serverless 产品。在存储方面,我们也推出了两款 Serverless 产品,第一款是和 OSS 对象存储团队联合合作推出的 OSS-HDFS ,全托管的 Serverless HDFS 产品。还有一款是数据湖管理构建产品中推出了完全兼容 HMS 协议的全托管的 Serverless 源数据管理的服务
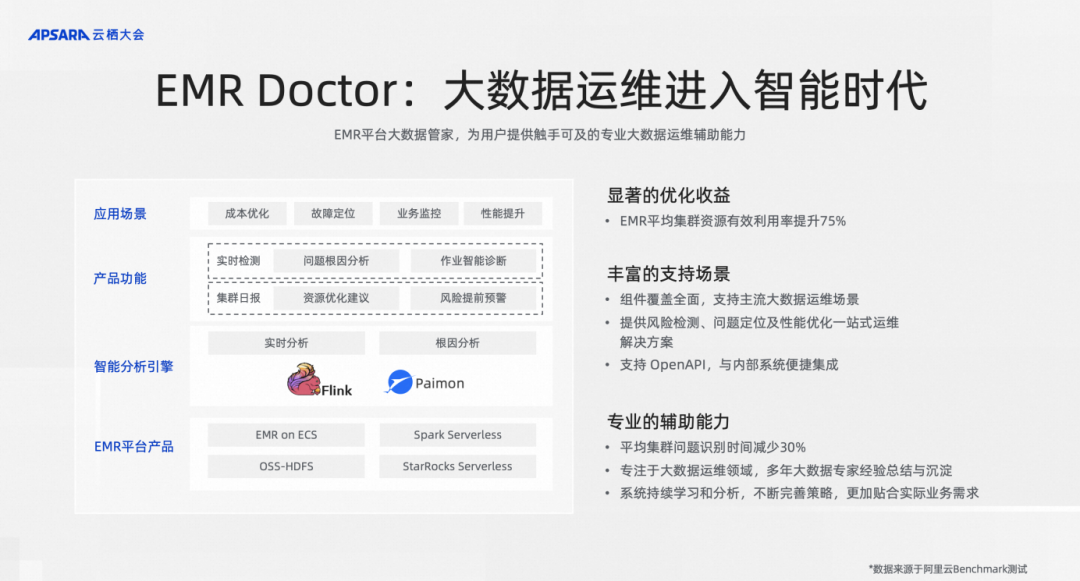
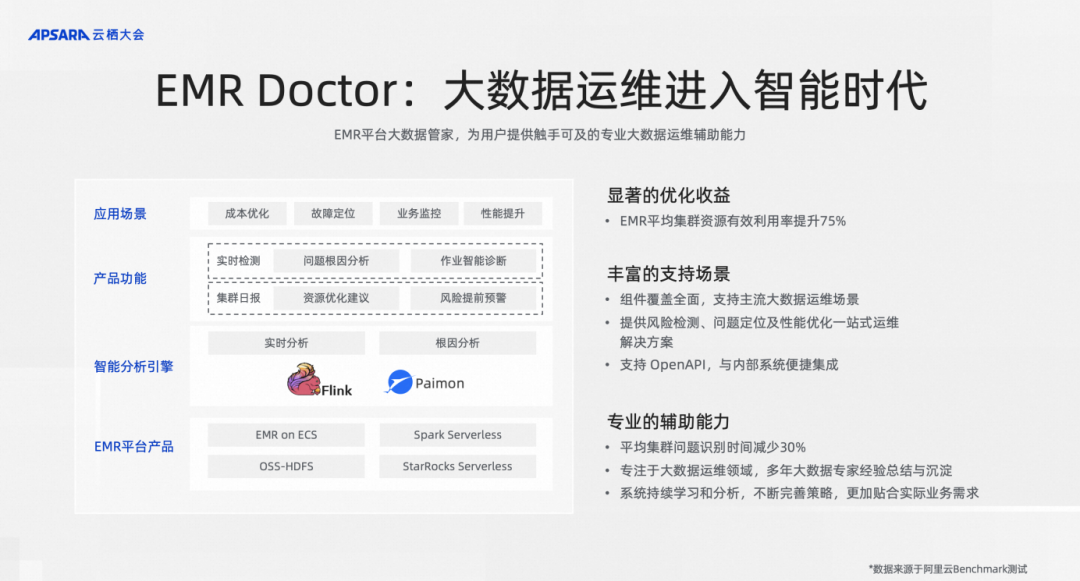
大家知道在 EMR 产品中运维是非常有挑战性的事情,因为 EMR 上有非常多的组件,Hadoop、Hive、Kafka、Spark、Flink、Presto 等,一旦系统出现问题怎么快速地定位问题,是一个非常让用户头疼的事情。甚至有时候即使没有出现问题,用户也希望对整个集群的资源利用率、存储效率进行提升。
之前完全都是靠人肉经验的去沉淀。前些年,我们也投入了很多的工程师帮助客户人肉解决这些问题,但近些年我们都把这些经验和知识沉淀成AI中的知识库、规则库,再结合一些传统机器学习算法和数据分析的方法,进行智能化定位问题,给用户建议,让用户优化集群,解决问题。