datahub 元数据博客摘录
DataHub: Popular metadata architectures explained
挺有意思的,在大数据领域多看看博客和论坛,会发现其实有一群人在反复研究相同的东西,大家都走过相同的路。如果多看看可以减少很多坑,可惜工作上并不会给你足够的时间,只要求赶紧看到成果。
这篇博客总结了metadata元数据管理领域的历史和挑战,用来说明为什么需要apache datahub,从里面看到不少曾经的困惑。
虽然现在大数据引擎到处都是,但是业务里会发现在一团乱麻里找数据才是最头疼的,metadata元数据管理平台的主要作用是让有用的数据能被快速找到,也就可以被称作数据资产平台。其实本质就是提供一个对数据库表进行搜索的的方法,可能还可以加上一些业务的tag标签用于便捷搜索。单个数据库的information schema没法快速查找到所有的信息,于是需要进行数据爬取,把库表元数据汇总到mysql/elasticsearch之类的地方进行汇总方便搜索。 接下来可能发现数据越来越多,于是mysql切换为elasticsearch。然后会发现爬取的数据存在时效性,客户新建的表压根就搜索不到,为了解决这个问题只能不断缩短爬取间隔。接下来会发现由于爬取频率太高,全量爬取数据量过大,仅仅一个元数据爬取就把高负载的数据库引擎搞崩了。接下来开始考虑增量爬取,开始考虑实时爬取,开始考虑从数据库订阅变更信息。为了解决时效性问题,有些场景需要切换为实时连接数据库进行show tables的查询。需要区分元数据可用的使用场景,不然时效性问题会导致用户对元数据系统不信赖,最后就是被废弃。
由于有以上各种问题, datahub出现了,全量采集功能有提供,额外的是考虑从云数据库订阅增量元数据变更信息,或者提供数据变更的api供外部调用。比如snowflake的数据库变更支持对外同步。对于不支持的,看起来还是要全量采集。 datahub对血缘数据的处理也是一样,提供了一个血缘api供外部提交,当前阶段本身并不支持对sql进行血缘解析。看起来datahub其实没什么特别的,就是定义好各种元数据定义,提供足够多的业务交互,然后让大家用起来。提供一种约定俗成的管理规范,其实逻辑能够自洽的话,会比杂七杂八的元数据管理平台省心不少。不过问题是datahub看起来交互都是国外互联网的样式,在传统公司估计很难用起来。
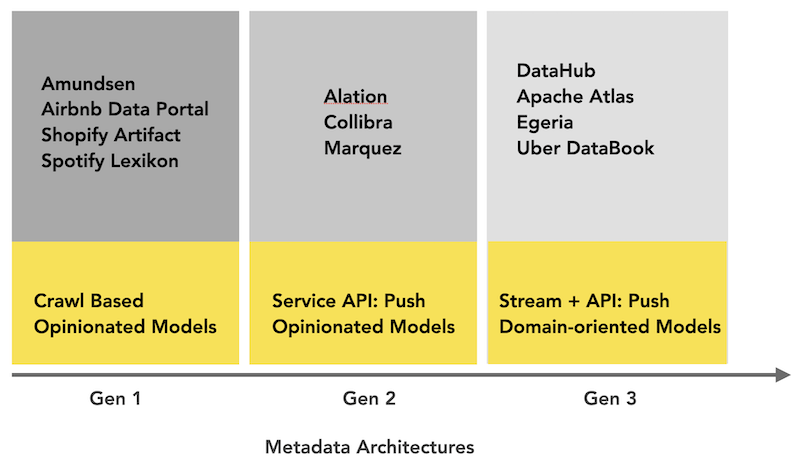
metadata管理平台走过的路是这样:数据太多找不到 -> 提供爬虫进行汇总支持搜索 -> 时效性问题导致信任度低 -> 增加爬取频率 -> 数据引擎由于爬虫导致高负载 -> 开始切换为实时增量采集。
博客摘录
其实主要是第一代的吐槽比较有意思,也是当前元数据管理平台的基本盘;后面的第二代和第三代就没看出什么特别的了,毕竟没有用过没什么感觉。第二三代只是加了一些push的api,data event消费,还是取决于外部平台的支持。
One of the first things I noticed was how often people were asking around for the “right dataset” to use for their analysis. It made me realize that, while we had built highly-scalable specialized data storage, streaming capabilities, and cost-efficient batch computation capabilities, we were still wasting time in just finding the right dataset to perform analysis.
用户其实不关心你的元数据管理平台是如何构建的,只要有个data catalog能支持对数据进行搜索管理就行。
Most data scientists don’t really care about how this tool actually works under the hood, as long as it enables them to be productive.
元数据管理平台的需求
元数据管理平台的常见需求,看了一下就是一个所谓的大数据治理平台需要提供的功能。最基础的元数据查询,数据源管理, 然后数据安全管控,数据血缘,分类分级,数据合规,AI可解释可重复(没看明白跟ai有什么关系),数据运维(数据流水线处理,数据统计),数据质量, 这些原来都可以算是metadata管理平台的需求,每天搬砖搬的就是这些。
Here are a few common use cases and a sampling of the kinds of metadata they need:
- Search and Discovery: Data schemas, fields, tags, usage information
- Access Control: Access control groups, users, policies
- Data Lineage: Pipeline executions, queries, API logs, API schemas
- Compliance: Taxonomy of data privacy/compliance annotation types
- Data Management: Data source configuration, ingestion configuration, retention configuration, data purge policies (e.g., for GDPR “Right To Be Forgotten”), data export policies (e.g., for GDPR “Right To Access”)
- AI Explainability, Reproducibility: Feature definition, model definition, training run executions, problem statement
- Data Ops: Pipeline executions, data partitions processed, data statistics
- Data Quality: Data quality rule definitions, rule execution results, data statistics
第一代元数据管理平台-pull模型
最常见的元数据管理平台,爬虫爬取metadata存储到数据库中,提供一个flask的web客户端供用户使用。 属于pull模型。
First-generation architecture: Pull-based ETL
一开始是mysql,后期可能会切换到图数据库用于支持血缘。
It is typically a classic monolith frontend (maybe a Flask app) with connectivity to a primary store for lookups (typically MySQL/Postgres), a search index for serving search queries (typically Elasticsearch), and, for generation 1.5 of this architecture, maybe a graph index for handling graph queries for lineage (typically Neo4j) once you hit the limits of relational databases for “recursive queries.”
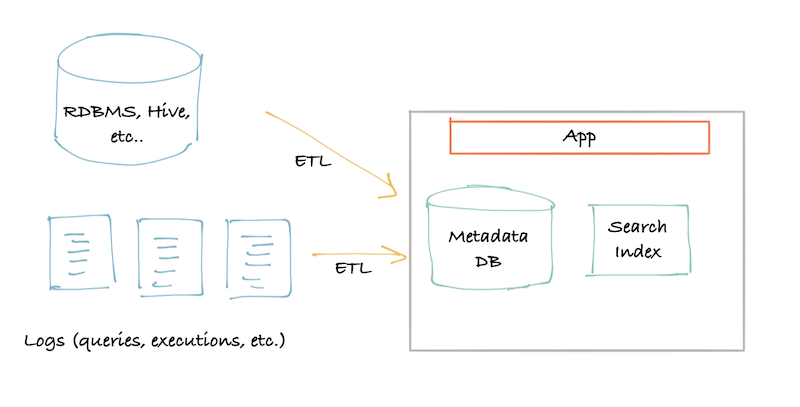
Metadata is typically ingested using a crawling approach by connecting to sources of metadata like your database catalog, the Hive catalog, the Kafka schema registry, or your workflow orchestrator’s log files, and then writing this metadata into the primary store, with the portions that need indexing added into the search index and the graph index.
爬取schema数据后,一般还需要对数据进行转化,方便存储到应用定义的元数据模型里。毕竟数据种类那么多,需要独立数据引擎自己定义一套新的元数据体系。
This crawling is typically a single process (non-parallel), running once a day or so. During this crawling and ingestion, there is often some transformation of the raw metadata into the app’s metadata model, because the data is rarely in the exact form that the catalog wants it.
高级版还能用spark进行批量爬取,同时还能计算关联性,支持推荐。
Slightly more advanced versions of this architecture will also allow a batch job (e.g., a Spark job) to process metadata at scale, compute relationships, recommendations, etc., and then load this metadata into the store and the indexes.
比较有意思的是作者的吐槽,比如半夜服务挂了,大家都会怀疑到元数据爬虫上来,不管三七二十一,先让爬虫暂停。后面事故恢复了也很少通知元数据爬虫恢复,于是元数据管理平台开始迟滞,最后大家就都不用了。
使用这种基础架构的开源产品
Amundsen employs this architecture, as did the original version of WhereHows that we open sourced in 2016. Among in-house systems, Spotify’s Lexikon, Shopify’s Artifact, and Airbnb’s Dataportal also follow the same architecture.
第二代管理平台-pull-push-模型
看起来就是提供一个api供外部写入元数据变更信息,没看出有什么特别的。
The service offers an API that allows metadata to be written into the system using push mechanisms, and programs that need to read metadata programmatically can read the metadata using this API. However, all the metadata accessible through this API is still stored in a single metadata store, which could be a single relational database or a scaled out key-value store.
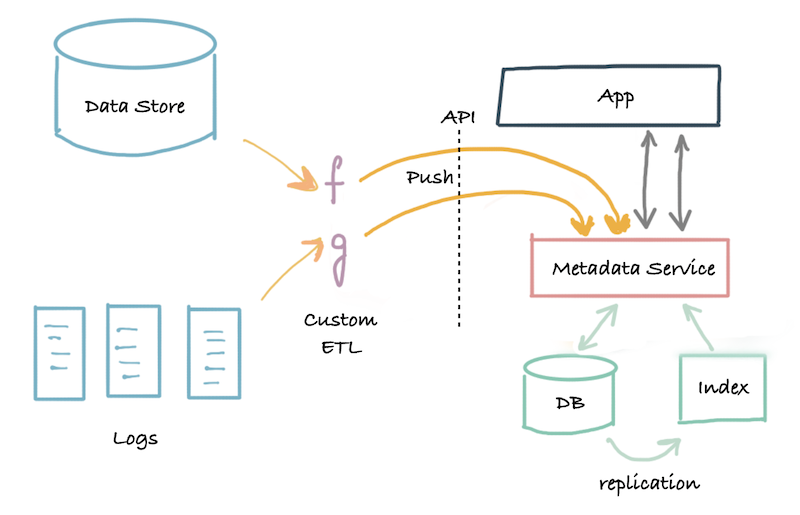
You still have to convince the producing team to emit metadata and take the dependency, but it is so much easier to do that with an agreed-upon schema.
好像是数据太多,导致元数据平台面临大数据平台相同的问题。
The operational impact of a service-based integration also results in tight coupling of the availability of the producer and the central service, which makes adopters nervous about adding one more source of downtime to their stack.
The central metadata team runs into the same issues that a central data warehouse team runs into。
第三代管理平台-Event-sourced metadata
The first is that the metadata itself needs to be free-flowing, event-based, and subscribable in real-time.The second is that the metadata model must support constant evolution as new extensions and additions crop up—without being blocked by a central team.
- Step 1: Log-oriented metadata architecture
Now that the log is the center of your metadata universe, in the event of any inconsistency, you can bootstrap your graph index or your search index at will, and repair errors deterministically.

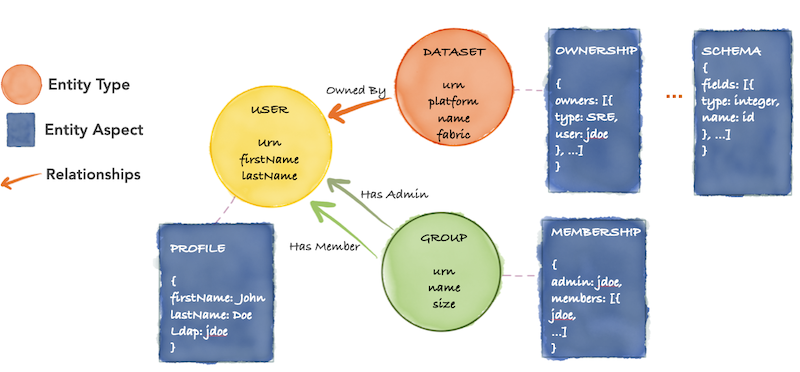
- Step 2: Domain-oriented decoupled metadata models
提交的元数据要求强类型定义,看起来主要是定义了要提交的元数据本身
Note that there can be various ways to describe these graph models, from RDF-based models to full-blown ER models to custom hybrid approaches like DataHub uses.
An example metadata model graph: Types, aspects, relationships
Third-generation architecture: End-to-end data flow
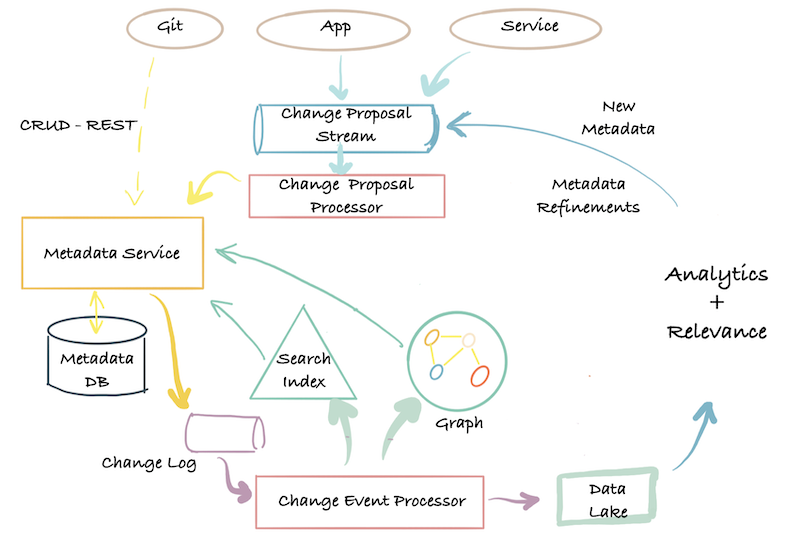
atlas竟然也是第三代平台。
The only ones that have a third-generation metadata architecture are Apache Atlas, Egeria, Uber Databook, and DataHub.