flink 架构入门
flink整体架构图
囫囵吞枣的快速入门记录下, 有需要还是看下官方文档了解下细节.
Anatomy of a Flink Cluster
https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/concepts/flink-architecture/
基础的架构肯定要了解一下. client用于提交任务, job manager用于接收然后派活, task manager用于干活, 干活的节点需要互相沟通以便能支持keyBy之类的数据交换需求.
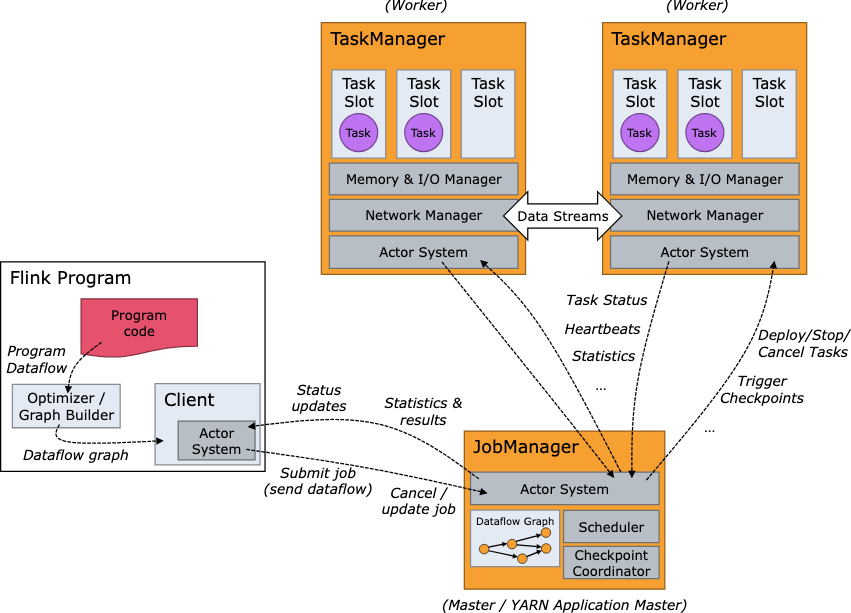
客户端client发送了任务后, 可以是异步离线模式(detached mode), 也就是不管不顾发送出去就完了; 也可以是挂载模式(attched mode), 可以持续接收任务状态信息.
jobManager和taskManager可以在物理机上单独运行, 也可以在yarn集群里接收资源分配, 分布式运行.
job manager
- ResourceManager: 分配资源, 管理task slots, 资源分配支持yarn/k8s/本地模式
The ResourceManager is responsible for resource de-/allocation and provisioning in a Flink cluster — it manages task slots.
- Dispatcher: 提供api接口, 接收任务后自动启动新的job master
The Dispatcher provides a REST interface to submit Flink applications for execution and starts a new JobMaster for each submitted job.
- JobMaster: 管理job graph.
A JobMaster is responsible for managing the execution of a single JobGraph.Multiple jobs can run simultaneously in a Flink cluster, each having its own JobMaster.
taskManagers
The TaskManagers (also called workers) execute the tasks of a dataflow, and buffer and exchange the data streams. The number of task slots in a TaskManager indicates the number of concurrent processing tasks.
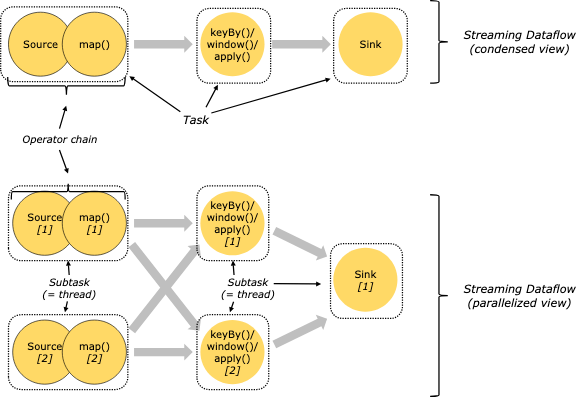
tasks and operator chains
任务流的交互, 每个任务task都是一个线程, 每个task里面可以有多个operator操作
For distributed execution, Flink chains operator subtasks together into tasks. Each task is executed by one thread.
The sample dataflow in the figure below is executed with five subtasks, and hence with five parallel threads. 下图从两个角度看问题, 总共有5个子任务, 5个并行线程.
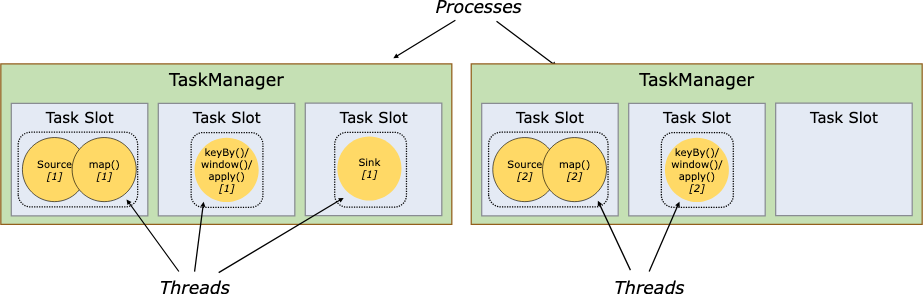
task slots and resources
每个worker(taskmanager)都是一个jvm进程, 一个tm能接受多少task线程, 取决于task slots的配置.
Each worker (TaskManager) is a JVM process, and may execute one or more subtasks in separate threads. To control how many tasks a TaskManager accepts, it has so called task slots (at least one).
目前slot只隔离限制了内存, 还没有去限制cpu.
Each task slot represents a fixed subset of resources of the TaskManager. A TaskManager with three slots, for example, will dedicate 1/3 of its managed memory to each slot. Slotting the resources means that a subtask will not compete with subtasks from other jobs for managed memory, but instead has a certain amount of reserved managed memory. Note that no CPU isolation happens here; currently slots only separate the managed memory of tasks.
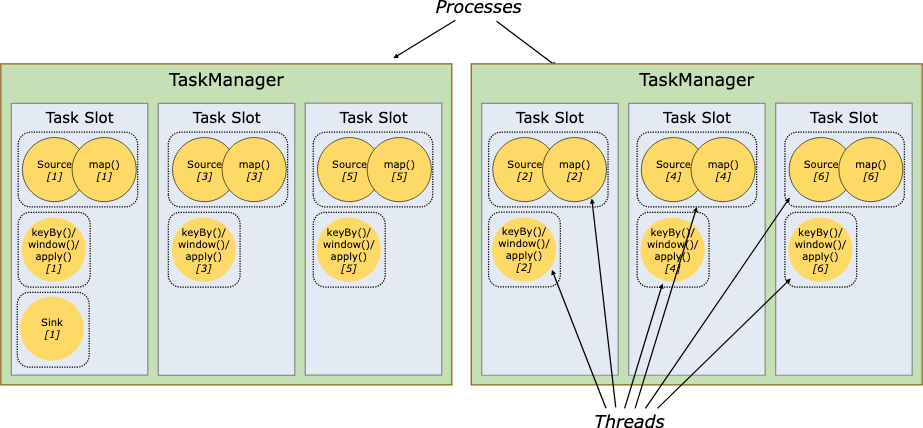
slot 支持在同一个job里共享, 因此一个slot就能运行一个job的整个完整流程
By default, Flink allows subtasks to share slots even if they are subtasks of different tasks, so long as they are from the same job. The result is that one slot may hold an entire pipeline of the job.
session cluster和application cluster
还是没能区别session cluster和per job cluster模式, 用到的时候再关注了...
flink有session cluster和application cluster. application cluster就是一个集群只用于一个任务, 好像是比较适应k8s模式. session cluste就比较符合认知, 又一个job manager在运行, 接收客户端提交的任务, 然后快速执行. 另外还有一种被淘汰的 flink job cluster, 每个任务启动一个新集群, 但已经不在支持了.
application cluster:
a Flink Application Cluster is a dedicated Flink cluster that only executes jobs from one Flink Application and where the main() method runs on the cluster rather than the client. The job submission is a one-step process: you don’t need to start a Flink cluster first and then submit a job to the existing cluster session; instead, you package your application logic and dependencies into a executable job JAR and the cluster entrypoint (ApplicationClusterEntryPoint) is responsible for calling the main() method to extract the JobGraph.
session cluster:
in a Flink Session Cluster, the client connects to a pre-existing, long-running cluster that can accept multiple job submissions. Even after all jobs are finished, the cluster (and the JobManager) will kee p running until the session is manually stopped. The lifetime of a Flink Session Cluster is therefore not bound to the lifetime of any Flink Job.
flink arch
What is Apache Flink? — Architecture
https://flink.apache.org/what-is-flink/flink-architecture/
流式数据里的有界流和无界流的概念
没有结束状态的流式数据为无界流, 比如每秒的天气情况. 无界流的数据次序一般比较重要, 因此需要有一些延时的watermark用来等待排序, 需要有window用来在这个时间段内进行汇总处理.有界流则可以等待所有数据到达, 然后再进行处理.
其实无界流可以分批次转化为有界流, 比如按每天来汇总计算每秒的天气情况, 非常符合逻辑. “每天”就是flink里的“window”窗口. 凌晨1点后再处理前一天的数据,那么“watermark”可以认为是“一个小时”, 延时1个小时内到达的传感器数据都会在前一天里进行处理.
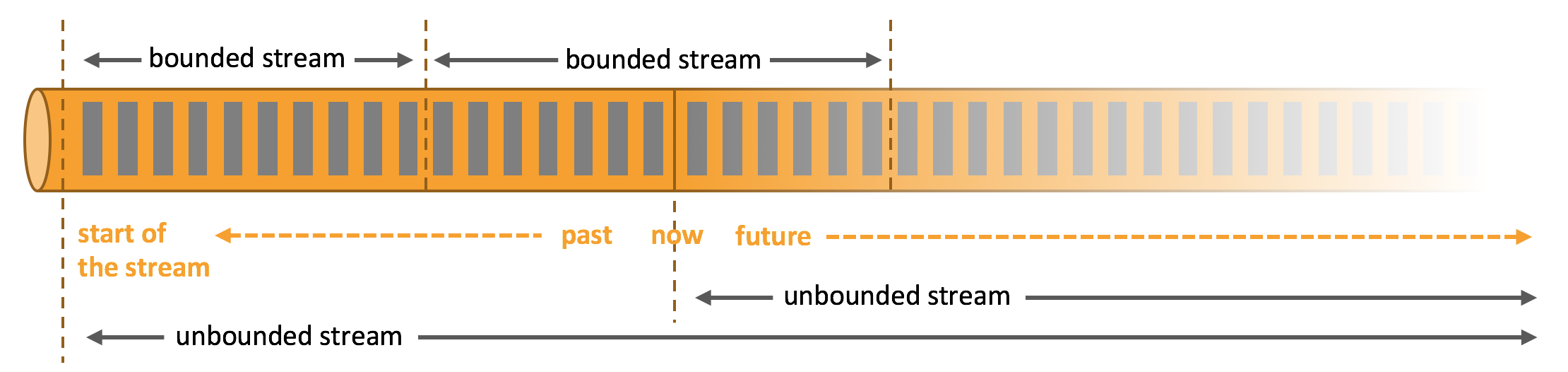
Data can be processed as unbounded or bounded streams.
Unbounded streams have a start but no defined end. Processing unbounded data often requires that events are ingested in a specific order, such as the order in which events occurred, to be able to reason about result completeness.
Bounded streams have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations. Ordered ingestion is not required to process bounded streams because a bounded data set can always be sorted. Processing of bounded streams is also known as batch processing.
流式状态的存储
流式状态会尽量保存在内存中, 若是内存不足以保存, 也会保存在磁盘里. 从fink的有状态处理来看, 有许多需要进行缓存以备批次处理的数据, 很明显非常消耗内存.
Stateful Flink applications are optimized for local state access. Task state is always maintained in memory or, if the state size exceeds the available memory, in access-efficient on-disk data structures.
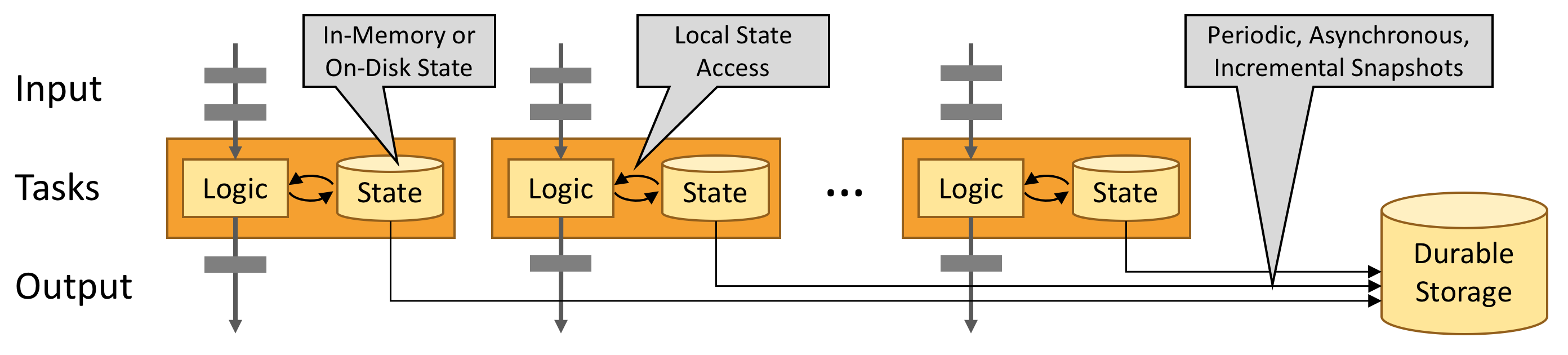
flink的 exactly-once state consistency 一次性状态, 依靠对流式状态的checkpoint存档来实现.
Flink guarantees exactly-once state consistency in case of failures by periodically and asynchronously checkpointing the local state to durable storage.
flink 常用概念
flink api 的层级
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/overview/
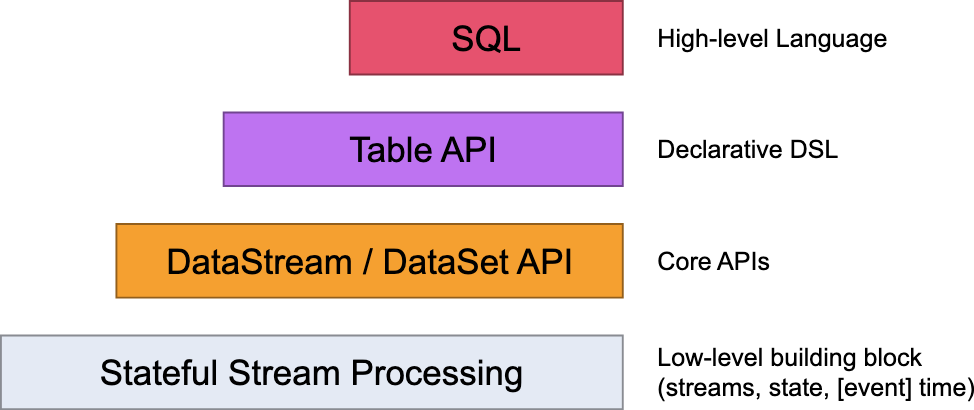
- Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用. 它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态
- Flink API 第二层抽象是 Core APIs
- Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API
- Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式