ranger 数据治理文章
到处看一看, 底层搬砖人总是在重复.
B站ranger数据治理
B站基于Apache Ranger的大数据权限服务的技术演进
https://mp.weixin.qq.com/s/MHrzfLKsTqjyCU7kPOKtkA
https://lrting.top/backend/8227/
看起来是2022年的文章, 介绍的都是摸爬过的坑, 还是值得沟通交流的, 主要信息点如下:
HDFS有约18万的policy,70万的policy item,200万的policy item access,去掉order by后load access可以节约4s左右的时间,整体load policy的时间在25s左右。 即使我们优化了load policy的逻辑,plugin权限生效的时间也要在25s以上,而且随着policy的增加,这个时间还将进一步增加,Ranger-2.0.0版本已经支持了增量Load Policy功能,下半年我们也会参考社区做增量化改造,降低权限生效时间,预估能到1s内。
从这个policy数量,可以猜出b站的策略估计是单资源模式, 比如估计每张表就一个策略. 同时从 policy item 数量, 可以猜测估计是每个用户单独授权, 并没有把多个用户的权限合并到一个policy item里面.
为了鉴权可以优雅的上线,减少因权限问题导致的任务失败,我们在HDFS plugin端增加了鉴权模式,支持按group(一个部门对应一个group)灰度上线鉴权功能,鉴权模式分为ALWAYS_ALLOW,ALWAYS_DENY和BY_HADOOP_ACL,鉴权时在没有匹配到policy的情况下才会用上述鉴权模式进行检查.
如果生产环境的集群一开始没有hdfs/hive鉴权, 一般都是后期发展起来了, 也有空了, 才会上线鉴权, 但这时候使用规模也大了, 许多任务都会中断, 用户就比较痛苦了. 看起来解决方法是改写了 ranger的hdfs鉴权逻辑, 在没有匹配到策略的时候, 判断用户是不是高级用户组, 是的话直接就通过了. 类似这些改造, 都得看过ranger鉴权源码, 比较熟悉了才知道可以这么搞. 其实还可以继续改, 高级用户组都不用判断策略了, 直接通过.
由于权限生效会有一定的延迟,工具侧在调用Ranger api赋权以后,没办法感知权限是否生效,往往会发生工单流程已经走完,用户还是没有的权限的情况。再者我们在排查user是否有一个路径权限时,可能会因为父路径权限的影响,排查起来会繁琐一些,因此我们在Admin端开发了权限预检查的接口,支持传入user,库表及相应的权限类型,返回权限检查是否成功。
看起来是个共同的痛点, 出现权限问题了需要快速排查到底哪里有问题, 是策略还没下载生效, 还是哪里的hdfs策略父级路径有问题. 工单多起来后, 安全团队只能自己开发, 调用一遍ranger的策略逻辑, 方便定位.
HDFS鉴权在使用的过程中遇到了一些问题,比如table owner没有权限drop自己的表情况,对于管理表来说,drop表时会删除相应的表路径,对于HDFS来说删除路径需要父路径的write权限,但是该用户又没有库的写权限,导致drop表失败。还有比如view的HDFS路径与相应表的HDFS路径是同一个,如果只回收表的权限,相当于回收了HDFS路径的权限,用户即使还有view的权限,在访问HDFS的时候就会失败。而且HDFS鉴权也只能到path级别,无法进行更细粒度的鉴权和数据脱敏,因此我们引入了Hive Table鉴权。Ranger各个service之前的policy是相互独立的,HDFS plugin在鉴权的时候只关心HDFS的policy,因此我们在Hive的授权的同时会将Hive的权限类型转换成HDFS的权限为HDFS赋权。
如果type是table,会根据resources中的table,通过Hive Metastore(HMS) client获取table location,再根据路径查找相关policy是否存在来决定是更新还是创建。
看起来B站的hive和hdfs权限是分开授权的, 同时管理hdfs和hive 就会带来各种琐碎的管理问题, 大家都逃不掉, 都要重头解决一遍. 比如这里看起来在授权hive的时候, 会到元数据里获取hive的table location, 然后顺便为hdfs授权.
Hive鉴权通过以后,任务访问HDFS还需要再经过HDFS的鉴权,这样就需要维护Hive和HDFS两份Policy,而且也不能解决前面提到的table owner无法删除自己的表的情况,下一步我们会将Hive Policy与HDFS Plugin融合起来,HDFS Plugin中维护一份table location数据,在检查路径权限时,首先检查路径对应的Hive Table是否有相应的权限,如果有就可以通过权限检查,如果没有匹配到table再检查HDFS Policy。
改写hdfs的ranger plugin, 在鉴权的时候先去判断是否有对应的hive权限, 可以避免许多hive/hdfs权限合作混乱的问题. 这个思路是不错的, 之前在其他企业的文章里也看到这种解决方案了.
Ranger所有的Plugin的load policy的机制都是相同的,需要请求Ranger Admin获取policy,将Policy缓存到内存并持久化到磁盘,这对于像HiveServer2,Spark Thrift Server和Kyuubi这样的长服务来说是可以接受的,但是对于像Hive Cli和Spark Sql这样的短任务,load policy会消耗大量的时间,内存和磁盘,也会增加Ranger Admin的负载。因此,我们将鉴权和脱敏的功能放到Hive Metastore 中去做,实现了一个类似于Hive Plugin的Hive MetaStore Plugin,Hive Metastore新增了鉴权和脱敏两个接口。
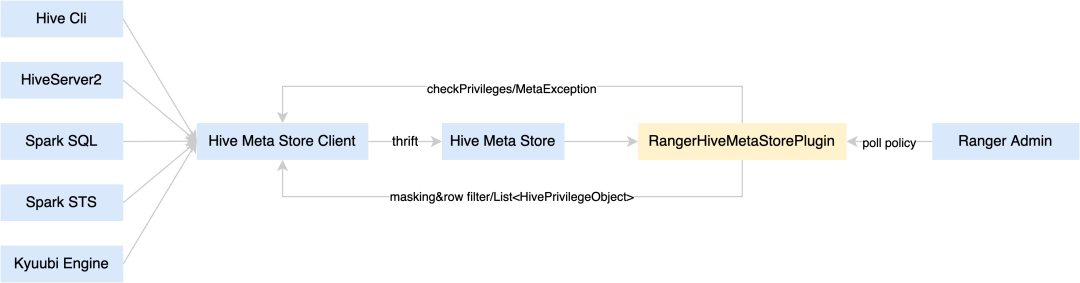
B站把ranger的策略从hive server切换到hive metastore, 不过hive metastore能够充分识别用户的操作是select还是delete吗? hive metastore鉴权, github上看已经有开源实现了, 不过没有仔细去阅读过.
Spark Ranger是通过inject Rule和Strategy解析plan来实现鉴权和脱敏的,改造成通过HMS鉴权,需要将SparkOperationType和SparkPrivilegeObject转换成对应的HiveOperationType和HivePrivilegeObject。
spark的ranger鉴权目前看到的开源思路都是解析执行计划logical plan来实现的, b站还进行了改造, 修改为metastore鉴权. 听起来有点猛, 不过之前看过的开源实践也是通过hmc实现spark的鉴权, 不知道是不是一回事?
鉴于Presto Coordinator为常驻服务,从Ranger Admin获取并加载policy所带来的消耗是可接受的,因此我们在Presto Ranger Plugin上进行改造。社区鉴权逻辑为:首先定期请求Ranger Admin获取Presto相关的policy并将其拉取到本地,其次在Presto每次进行语义分析的时候,对当前表及字段的权限进行校验。对上述鉴权逻辑进行分析,我们不难发现社区的鉴权方式需要在Admin侧单独维护Presto相关的policy,而在我们的场景中大部分的权限需求还是在Hive中,为不同引擎各自维护一套policy无疑会增加运维成本,因此我们对其做了些改造,使其兼容Hive的policy。其实现方式并不复杂,一方面,将拉取Presto policy替换为拉取Hive policy;另一方面,将原先Presto plugin的3段式进行改造兼容Hive的格式。目前我们的Presto Ranger支持了表/字段、column masking和row filter的权限控制。
ranger提供了preso的plugin插件, 不过与hive plugin归属不同类型, 无法共用policy, 估计一个平台需要维护两份. 看起来B站修改了prestor ranger的插件, 直接获取hive的策略policy, 改造为兼容hive的database/table/column格式, 那就没问题了.
目前我们Spark和Hive已经全接入了HMS鉴权和数据脱敏,对于数据脱敏中的column masking,我们正在用的策略(部分)有:
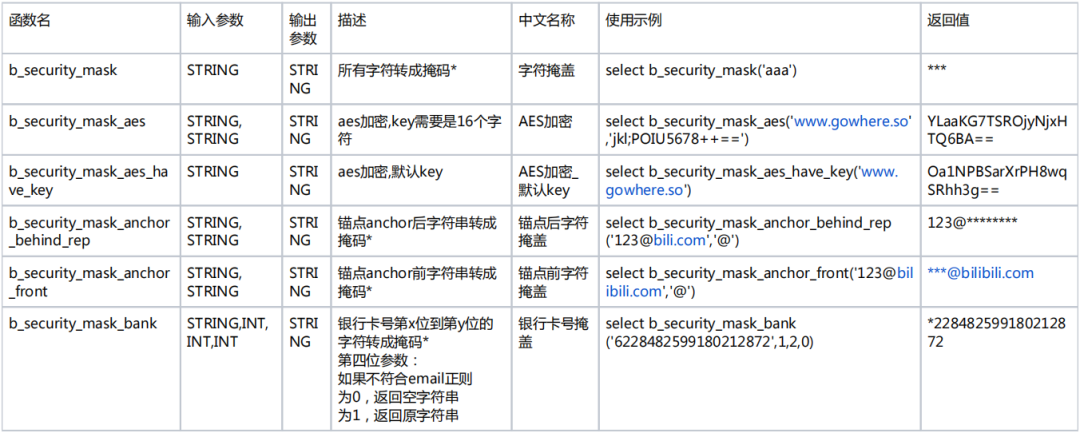
看起来b站在hms ranger上实现了spark的column masking, 得先看下ranger masking和spark hms 插件源码再来评估.
字段权限没看到介绍, 不知道在业务里是否有实现?
有赞大数据治理
有赞大数据平台安全建设实践
https://tech.youzan.com/bigdatasafety/
2018年的文章, 算是比较久远了, 主要的信息点如下
授权部分
- 使用ranger hiverserver2进行鉴权
- 提供统一授权平台, 在内部的授权平台上操作, 然后后台再去操作ranger
数据脱敏部分
使用ranger 脱敏相同的技术方向, sql重写实现数据脱敏, 脱敏配置也是在ranger上配. 不过看起来像是额外实现了一个模块去处理, 通过 sql antlr4 解析改写了sql. 支持spark和presto, 由于hive语法文件是antlr3版本, 还用antlr4改写一遍hive语法, 真是有空啊. 由于血缘也是通过sql解析而来, 有赞在处理sql解析重写的时候, 顺便把血缘解析也给做了, 再次感慨, 真是有空啊. 记得阿里的druid也是自己实现了一套解析方案, 方便做血缘处理.
业务上也有值得借鉴的地方, 比如如果某些字段被定义为三级分类, 自动应用默认的脱敏规则. 联动效果比较合理, 这样就不用一个个手动去配置了. 而且字段也通过血缘实现了连动, 整条血缘路线同一个字段来源的都应用相同的脱敏规则. 很多技术文档大家都是这么宣传血缘的应用的, 但是真的完整实现这些业务功能的, 还是挺少见的.
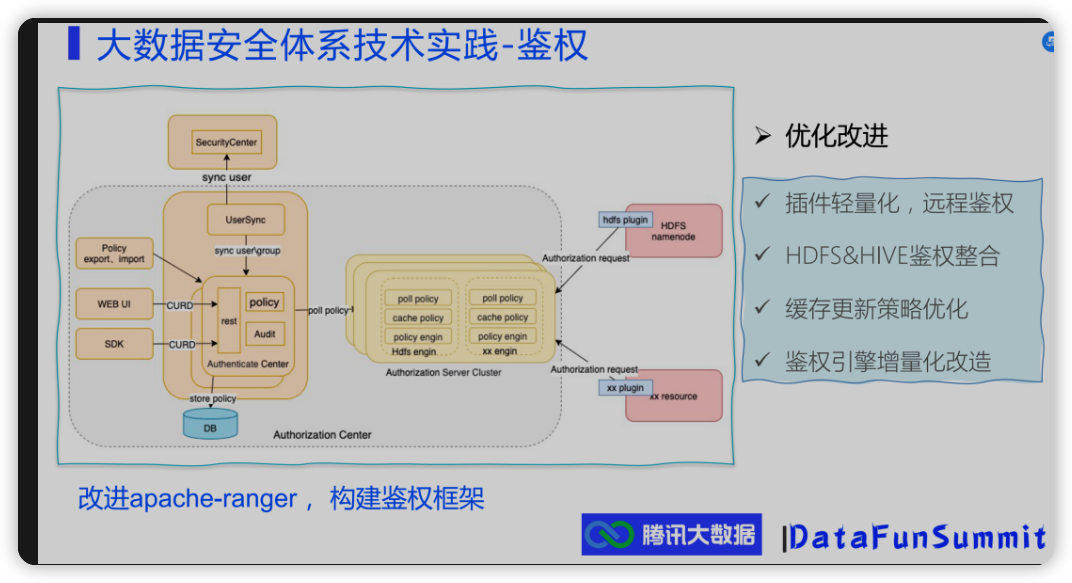
腾讯数据治理
看起来是2021年对外公开的宣讲ppt, 主要是宽泛的介绍.
- hdfs&hive鉴权整合.
- 看起来不通过ranger plugin本地缓存鉴权了, 而是统一远程鉴权?
腾讯——大数据安全体系介绍
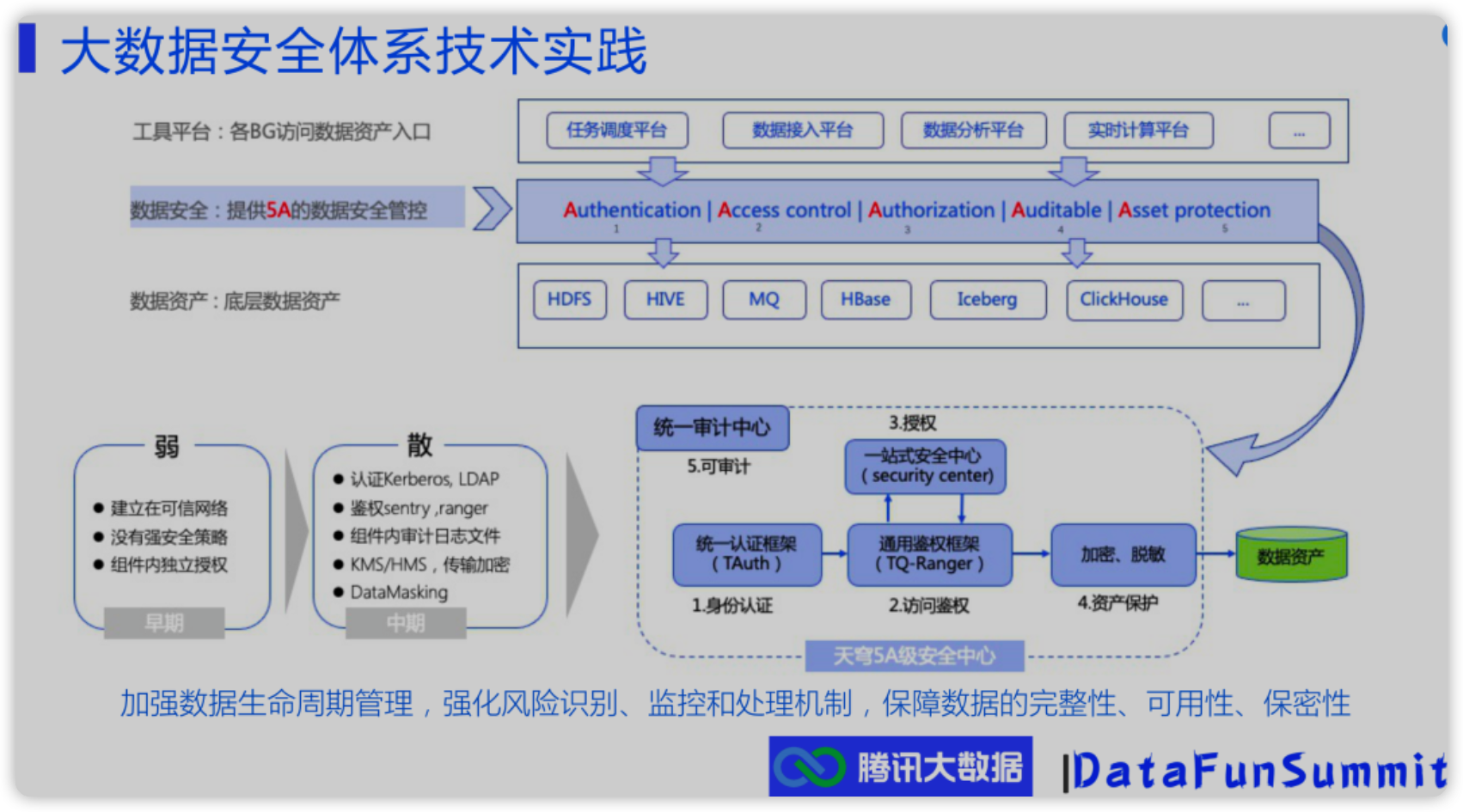
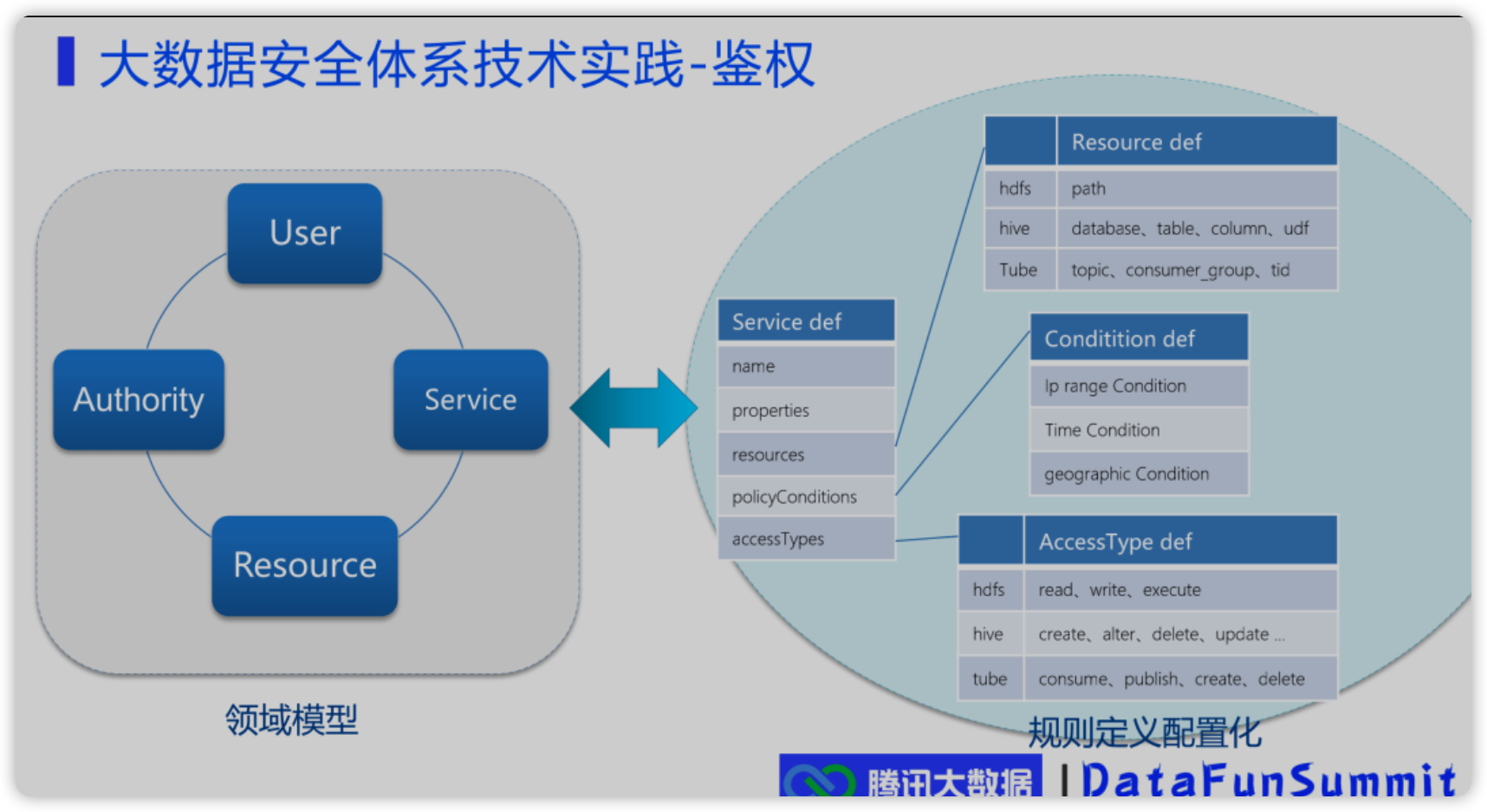
网易数帆的技术分享
update: 看到了网易数凡在2023年的分享文章, 非常赞. 很多细节都是真实面临的问题, 这个领域需要面对解决的问题, 许多人早就解决过了. 看起来是扎扎实实一步一步在做数据治理的产品, 想起来apache kyuubi也是网易出品的, 那些到处瞎搞纯捞钱的公司可没有精力搞这种开源组件.
网易基于Apache Ranger的数据安全中心实践
https://www.secrss.com/articles/55600
快速摘录的知识点:
- 部分自定义的ranger插件, 将plugin的policy鉴权修改为web调用, 而不是本地缓存, 看起来与前面腾讯的方案相同. 解决了十百万级策略数量下policy占用组件内存的问题, 但引入的问题是如果组件与安全平台部署过远, 鉴权速度会有问题.
- 大家都会遇到所谓管理平台与ranger策略一致性的问题, 网易解决思路是只写入ranger, 读取的话则从ranger定时同步到安全平台自己的缓存中. 虽然有时间差, 但是高一致性.
- 大家都会遇到的ranger不支持搜索某个用户有哪些权限, ranger admin本身bug多 api速度慢的问题, 网易的思路是自己构建权限模型, 从ranger缓存策略到自己的权限模型上. 一些读取和筛选的操作, 就都在自己的权限模型上进行操作, 这样自由度就非常高了. ranger作为最终一致性的管控中心, 只负责权限的写入.
- 大家都会遇到某些高级企业用户就是想要自己管控ranger策略的问题, 不想由定制化的平台去接管. 这样就触发了一个需求, 在ranger里的管控需要体现在自己的安全平台上, 同时安全平台不能自己去实现一些隐含的自定义权限. 网易开放了ranger的接口, 另外前面的policy一致性管理策略也刚好解决了这个问题, 写入都到ranger中, 安全平台只会定时从ranger读取policy作为缓存. 不过这里还是有个问题,安全平台如果还要支持授权回收/角色管理权限等业务需求, 如何保持与ranger里的一致呢, 难道安全平台本身只能做policy的缓存中介?
- hdfs权限的w包含了delete, 网易改写了权限请求, 并且设置了安全目录禁止删除
- 动态脱敏部分的解决方案也不错, 在ranger里记录的只是一个脱敏策略的标识, 具体的脱敏算法由平台提供. 同时提供白名单用户机制, 某张表白名单里的用户就不用走脱敏了. 高级用户的需求挺广泛的.
- 大家都会遇到权限策略管理问题, 比如无效权限, 冗余权限. 网易是做了权限的管理平台, 并且在审计环节记录权限的使用情况, 可以分析出长时间没用的无效权限. 看起来网易也使用了用户角色去管理权限, 审计平台补全了权限是通过用户还是角色的命中拦截信息.
- hdfs和hive的负责人ownership权限管理问题, 看起来网易也摸索过了. 比如hdfs的递归owner问题, hive metastore的owner字段会被低版本spark污染问题, 网易自己在元数据平台维护了用户负责人, 鉴权的时候需要从元数据平台补全负责人信息. 这里看来实现了元数据采集管理平台与安全鉴权平台的联动. 看起来网易之前也是一张表一条policy记录,有了owner负责人字段后, policy数量可以大量减少, 毕竟可以用库表模糊匹配一条策略授权owner就可以了.
- spark的ranger鉴权和脱敏问题, 看起来是从logical plan执行计划里解析出对应的字段, 再调用原来的逻辑进行处理. 看起来非常熟悉, 最近在kyuubi里看到的鉴权和脱敏插件就是这个思路, 这时候想起来kyuubi就是网易数帆出品的开源组件.
- ranger 里到处都是小bug, 看过ranger源码就有这种感觉了, 尤其是混乱的admin部分.
- 商业化部分也是很有感触, 安全平台需要对接内部产品和外部客户, 这时候就出现了一个问题, 公司内部可以去改造大数据组件进行部署, 但是外部可能只能提供对接开源大数据组件. 对于平台型的大数据产品而言, 很多时候就是这么纠结, 很多方案不能用, 只能把大数据组件开源提供的方案上进行构建.