ranger hive 列脱敏与行筛选
列脱敏和行筛选, 没想到都是数据权限管控的领域, 都是ranger提供的基本功能. 使用起来非常直观, 基本原理以前也看过一些文档了, 实现方案都是改写sql, 但是没看到技术细节没看到代码还是不稳妥. 浏览ranger 鉴权代码的时候, 也没看到怎么改写hive sql的内容, 总觉得世界的迷雾没有破开. 一番搜索, 发现原来底层是hive实现的, ranger基本上只提供了策略的管理和调用. 这套流程嵌入在hive的checkPrivilege鉴权请求流程里, 打得一手好配合.
简单的原理介绍下. 对于列级筛选, 只需要在sql的语句里添加where col in (a,b,c)之类的筛选即可. 对于列脱敏, 则是在搜索处将对应表的字段进行转换, 然后再进行搜索. 语句从select a from tableb变成 select a from (select mask(a), b from tableb). hive的实现, 看起来是在鉴权的时候获取到需要进行改写的策略内容, 然后修改自身的sql解析, 直接把脱敏筛选策略通过udf函数加入到sql里. 毕竟hive server的主要功能就是做sql解析, 改写下sql对他们来说轻轻松松. 脱敏能够支持的方案, 其实也取决于hive所支持的脱敏udf函数.
问题来了, 非hive的引擎在ranger里是如何实现脱敏和筛选呢? hive的脱敏对于只是用hive metastore的 sparksql是否能生效? 这些就得后面有需要再调研查看了.
一些参考文档
ranger cwiki: Row-level filtering and column-masking using Apache Ranger policies in Apache Hive
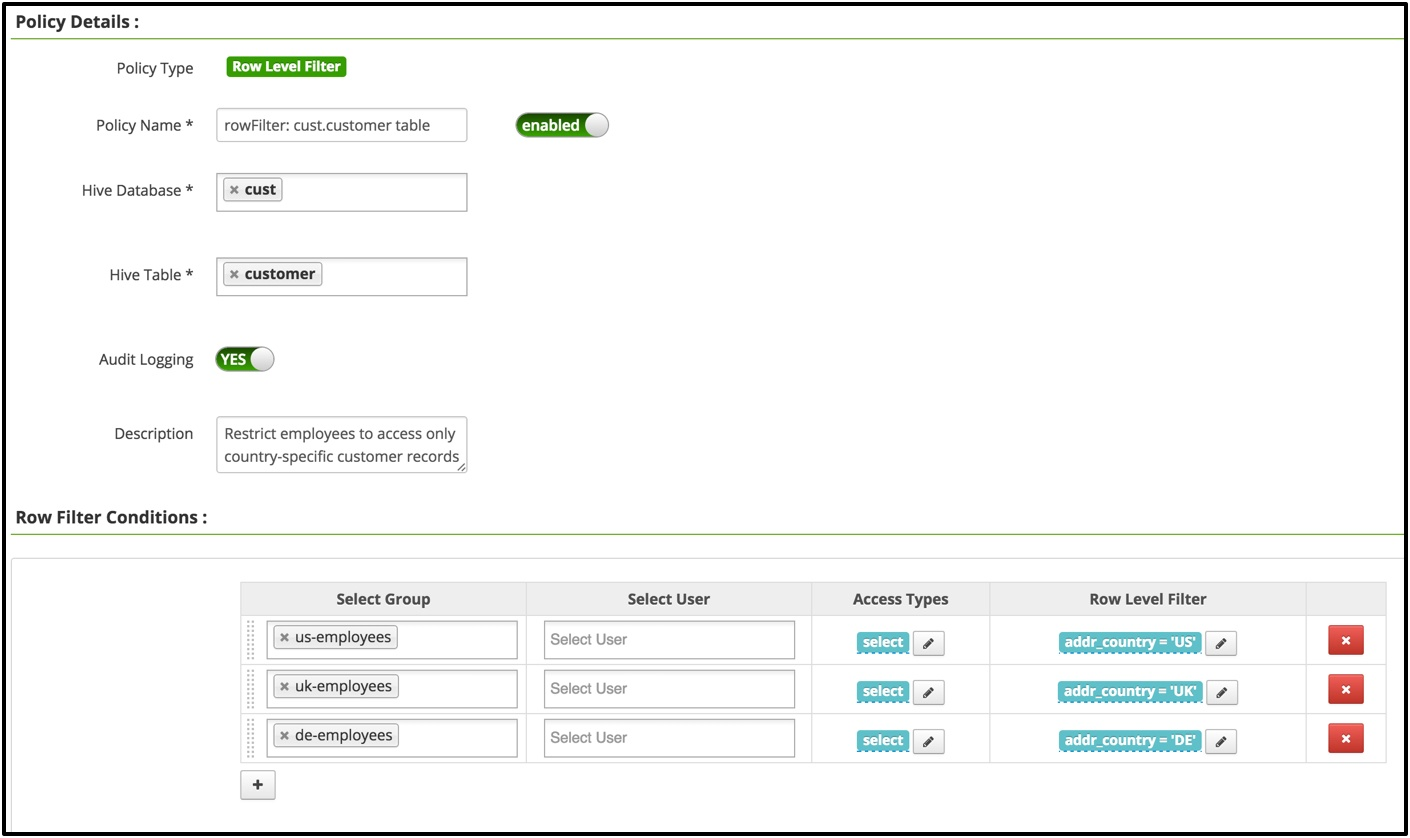
行筛选的用法
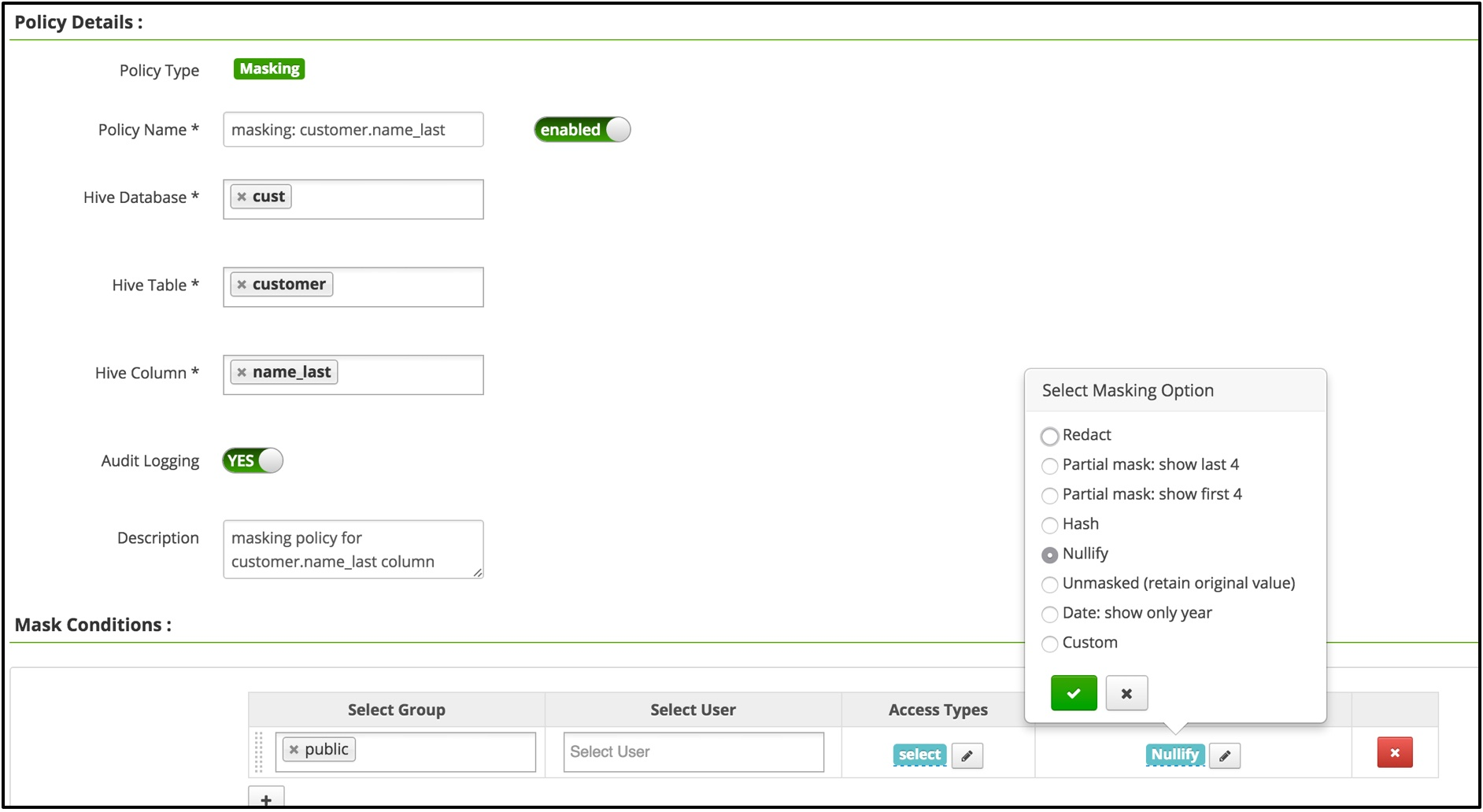
列脱敏的用法
- Policy Model
This section summarizes the updates to Apache Ranger policy model to support row-filter and data-mask features.
- Support for two new policy-types has been added: row-filter and data-mask
- RangerServiceDef, the class that represents a service/component (like HDFS/Hive/HBase, ..), has been updated with addition of two attributes – rowFilterDef and dataMaskDef. Services that need row-filter or data-masking feature should populate these attributes with appropriate values
- RangerPolicy, the class that represents a policy in Apache Ranger, has been updated with addition of two attributes – rowFilterPolicyItems and dataMaskPolicyItems. References
- RangerPolicyEngine interface has been updated with two new methods, evalRowFilterPolicies() and evalDataMaskPolicies(). Corresponding implementations have been added to RangerPolicyEngineImpl and other related classes.
References, hive和ranger同时贡献了这个特性, hive在2.1版本之后支持.
HIVE-13125: Support masking and filtering of rows/columns HIVE-13568: Add UDFs to support column-masking RANGER-873: Ranger policy model to support data-masking RANGER-908: Ranger policy model to support row-filtering RANGER-895: Ranger Hive plugin to support column-masking RANGER-909: Ranger Hive plugin to support row-filtering
- Can wildcards or multiple-values be used to specify database/table/column in row-filtering and data-masking policies?
无法使用模糊匹配定义脱敏策略, 需要指明具体的库表列.
Use of wildcards or multiple-values to specify database/table/column values is not supported in row-filtering and data-masking policies. Row-filter expressions often refer to columns in the same table; such expressions may not be applicable for other tables, making wildcards/multiple-values less useful or more error-prone here.
- How are operations like insert, update and delete are handled when the user has row-filter/column-masking on the table/columns?
如果有脱敏和筛选策略, 用户无法变更对应的库表.
Operations insert/update/delete/export are denied for users if row-filter or column-masking policies are applicable on the table for the user.
ranger issue: Ranger Hive plugin to support column-masking
ranger 0.6 版本就支持了脱敏和行筛选功能.
Ranger Hive plugin to support column-masking
https://issues.apache.org/jira/browse/RANGER-895
Apache Hive 2.1.0 has updated HiveAuthorizer interface to support column-masking and row-level filtering. Ranger Hive plugin should be updated to implement the new methods to provide column-masking. Updates to support row-level filtering will be tracked via a separate JIRA.
hive issue: Support masking and filtering of rows/columns
以前要实现列脱敏和行筛选, 一般通过hive views来曲线实现, 因为views视图背后可以写复杂的sql函数进行数据表的转换. 当要求越来越复杂之后, 使用hive views来管理也越来越麻烦, 最终就产生了使用ranger实现对的列脱敏和行筛选的需求.
Support masking and filtering of rows/columns
https://issues.apache.org/jira/browse/HIVE-13125
Traditionally, access control at the row and column level is implemented through views. Using views as an access control method works well only when access rules, restrictions, and conditions are monolithic and simple. It however becomes ineffective when view definitions become too complex because of the complexity and granularity of privacy and security policies. It also becomes costly when a large number of views must be manually updated and maintained. In addition, the ability to update views proves to be challenging. As privacy and security policies evolve, required updates to views may negatively affect the security logic particularly when database applications reference the views directly by name. HIVE row and column access control helps resolve all these problems.
具体修改代码, 可以看到修改了语法解析树.
https://issues.apache.org/jira/secure/attachment/12794418/HIVE-13125.final.patch
@Override
void setInsertToken(ASTNode ast, boolean isTmpFileDest) {
}
}
+ private Table getMetaDataTableObjectByName(String tableName) throws HiveException {
+ if (!tableNameToMetaDataTableObject.containsKey(tableName)) {
+ Table table = db.getTable(tableName);
+ tableNameToMetaDataTableObject.put(tableName, table);
+ return table;
+ } else {
+ return tableNameToMetaDataTableObject.get(tableName);
+ }
+ }
+
+ private void walkASTMarkTABREF(ASTNode ast, Set<String> cteAlias)
+ throws SemanticException {
+ Queue<Node> queue = new LinkedList<>();
+ queue.add(ast);
+ while (!queue.isEmpty()) {
+ ASTNode astNode = (ASTNode) queue.poll();
+ if (astNode.getToken().getType() == HiveParser.TOK_TABREF) {
+ int aliasIndex = 0;
+ StringBuffer additionalTabInfo = new StringBuffer();
+ for (int index = 1; index < astNode.getChildCount(); index++) {
+ ASTNode ct = (ASTNode) astNode.getChild(index);
+ // TODO: support TOK_TABLEBUCKETSAMPLE, TOK_TABLESPLITSAMPLE, and
+ // TOK_TABLEPROPERTIES
+ if (ct.getToken().getType() == HiveParser.TOK_TABLEBUCKETSAMPLE
+ || ct.getToken().getType() == HiveParser.TOK_TABLESPLITSAMPLE
+ || ct.getToken().getType() == HiveParser.TOK_TABLEPROPERTIES) {
+ additionalTabInfo.append(ctx.getTokenRewriteStream().toString(ct.getTokenStartIndex(),
+ ct.getTokenStopIndex()));
+ } else {
+ aliasIndex = index;
+ }
+ }
+
+ ASTNode tableTree = (ASTNode) (astNode.getChild(0));
+
+ String tabIdName = getUnescapedName(tableTree);
+
+ String alias;
+ if (aliasIndex != 0) {
+ alias = unescapeIdentifier(astNode.getChild(aliasIndex).getText());
+ } else {
+ alias = getUnescapedUnqualifiedTableName(tableTree);
+ }
+
+ // We need to know if it is CTE or not.
+ // A CTE may have the same name as a table.
+ // For example,
+ // with select TAB1 [masking] as TAB2
+ // select * from TAB2 [no masking]
+ if (cteAlias.contains(tabIdName)) {
+ continue;
+ }
+
+ String replacementText = null;
+ Table table = null;
+ try {
+ table = getMetaDataTableObjectByName(tabIdName);
+ } catch (HiveException e) {
+ throw new SemanticException("Table " + tabIdName + " is not found.");
+ }
+
+ if (tableMask.needTransform(table.getDbName(), table.getTableName())) {
+ replacementText = tableMask.create(table, additionalTabInfo.toString(), alias);
+ }
+ if (replacementText != null) {
+ tableMask.setNeedsRewrite(true);
+ // we replace the tabref with replacementText here.
+ tableMask.addTableMasking(astNode, replacementText);
+ }
+ }
+ if (astNode.getChildCount() > 0 && !ignoredTokens.contains(astNode.getToken().getType())) {
+ for (Node child : astNode.getChildren()) {
+ queue.offer(child);
+ }
+ }
+ }
+ }
+
+ // We walk through the AST.
+ // We replace all the TOK_TABREF by adding additional masking and filter if
+ // the table needs to be masked or filtered.
+ // For the replacement, we leverage the methods that are used for
+ // unparseTranslator.
+ public ASTNode rewriteASTWithMaskAndFilter(ASTNode ast) throws SemanticException {
+ // 1. collect information about CTE if there is any.
+ // The base table of CTE should be masked.
+ // The CTE itself should not be masked in the references in the following main query.
+ Set<String> cteAlias = new HashSet<>();
+ if (ast.getChildCount() > 0
+ && HiveParser.TOK_CTE == ((ASTNode) ast.getChild(0)).getToken().getType()) {
+ // the structure inside CTE is like this
+ // TOK_CTE
+ // TOK_SUBQUERY
+ // sq1 (may refer to sq2)
+ // ...
+ // TOK_SUBQUERY
+ // sq2
+ ASTNode cte = (ASTNode) ast.getChild(0);
+ // we start from sq2, end up with sq1.
+ for (int index = cte.getChildCount() - 1; index >= 0; index--) {
+ ASTNode subq = (ASTNode) cte.getChild(index);
+ String alias = unescapeIdentifier(subq.getChild(1).getText());
+ if (cteAlias.contains(alias)) {
+ throw new SemanticException("Duplicate definition of " + alias);
+ } else {
+ cteAlias.add(alias);
+ walkASTMarkTABREF(subq, cteAlias);
+ }
+ }
+ // walk the other part of ast
+ for (int index = 1; index < ast.getChildCount(); index++) {
+ walkASTMarkTABREF((ASTNode) ast.getChild(index), cteAlias);
+ }
+ }
+ // there is no CTE, walk the whole AST
+ else {
+ walkASTMarkTABREF(ast, cteAlias);
+ }
+ // 2. rewrite the AST, replace TABREF with masking/filtering
+ if (tableMask.needsRewrite()) {
+ tableMask.applyTableMasking(ctx.getTokenRewriteStream());
+ String rewrittenQuery = ctx.getTokenRewriteStream().toString(ast.getTokenStartIndex(),
+ ast.getTokenStopIndex());
+ ASTNode rewrittenTree;
+ // Parse the rewritten query string
+ // check if we need to ctx.setCmd(rewrittenQuery);
+ ParseDriver pd = new ParseDriver();
+ try {
+ rewrittenTree = pd.parse(rewrittenQuery);
+ } catch (ParseException e) {
+ throw new SemanticException(e);
+ }
+ rewrittenTree = ParseUtils.findRootNonNullToken(rewrittenTree);
+ return rewrittenTree;
+ } else {
+ return ast;
+ }
+ }
+
判断权限的时候, ranger除了返回是否有权限, 还会返回需要转换的脱敏策略信息. 根据ranger返回的鉴权信息, 判断是否需要进行转换(transform), 然后语法解析开始干活.
Object getHiveAuthorizationTranslator() throws HiveAuthzPluginException;
+ /**
+ * TableMaskingPolicy defines how users can access base tables. It defines a
+ * policy on what columns and rows are hidden, masked or redacted based on
+ * user, role or location.
+ */
+ /**
+ * getRowFilterExpression is called once for each table in a query. It expects
+ * a valid filter condition to be returned. Null indicates no filtering is
+ * required.
+ *
+ * Example: table foo(c int) -> "c > 0 && c % 2 = 0"
+ *
+ * @param database
+ * the name of the database in which the table lives
+ * @param table
+ * the name of the table in question
+ * @return
+ * @throws SemanticException
+ */
+ public String getRowFilterExpression(String database, String table) throws SemanticException;
+
+ /**
+ * needTransform() is called once per user in a query. If the function returns
+ * true a call to needTransform(String database, String table) will happen.
+ * Returning false short-circuits the generation of row/column transforms.
+ *
+ * @return
+ * @throws SemanticException
+ */
+ public boolean needTransform();
+
+ /**
+ * needTransform(String database, String table) is called once per table in a
+ * query. If the function returns true a call to getRowFilterExpression and
+ * getCellValueTransformer will happen. Returning false short-circuits the
+ * generation of row/column transforms.
+ *
+ * @param database
+ * the name of the database in which the table lives
+ * @param table
+ * the name of the table in question
+ * @return
+ * @throws SemanticException
+ */
+ public boolean needTransform(String database, String table);
+
+ /**
+ * getCellValueTransformer is called once per column in each table accessed by
+ * the query. It expects a valid expression as used in a select clause. Null
+ * is not a valid option. If no transformation is needed simply return the
+ * column name.
+ *
+ * Example: column a -> "a" (no transform)
+ *
+ * Example: column a -> "reverse(a)" (call the reverse function on a)
+ *
+ * Example: column a -> "5" (replace column a with the constant 5)
+ *
+ * @param database
+ * @param table
+ * @param columnName
+ * @return
+ * @throws SemanticException
+ */
+ public String getCellValueTransformer(String database, String table, String columnName)
+ throws SemanticException;
+
}
hive issue: Add UDFs to support column-masking
脱敏能支持的类型, 都是有hive udf函数实现的.
Add UDFs to support column-masking
https://issues.apache.org/jira/browse/HIVE-13568
HIVE-13125 added support to provide column-masking and row-filtering during select via HiveAuthorizer interface. This JIRA is track addition of UDFs that can be used by HiveAuthorizer implementations to mask column values.
Attached patch HIVE-13568.1 adds the following 6 UDFs:
- mask()
- mask_first_n()
- mask_last_n()
- mask_hash()
- mask_show_first_n()
- mask_show_last_n()
脱敏的udfs函数的写法, 可以根据提交的代码快速进行了解.
https://issues.apache.org/jira/secure/attachment/12801694/HIVE-13568.4.patch
比如文本转换和数字转换
+class StringTransformerAdapter extends AbstractTransformerAdapter {
+ final StringObjectInspector columnType;
+ final Text writable;
+
+ public StringTransformerAdapter(StringObjectInspector columnType, AbstractTransformer transformer) {
+ this(columnType, transformer, new Text());
+ }
+
+ public StringTransformerAdapter(StringObjectInspector columnType, AbstractTransformer transformer, Text writable) {
+ super(transformer);
+
+ this.columnType = columnType;
+ this.writable = writable;
+ }
+
+ @Override
+ public Object getTransformedWritable(DeferredObject object) throws HiveException {
+ String value = columnType.getPrimitiveJavaObject(object.get());
+
+ if(value != null) {
+ String transformedValue = transformer.transform(value);
+
+ if(transformedValue != null) {
+ writable.set(transformedValue);
+
+ return writable;
+ }
+ }
+
+ return null;
+ }
+}
+
+class IntegerTransformerAdapter extends AbstractTransformerAdapter {
+ final IntObjectInspector columnType;
+ final IntWritable writable;
+
+ public IntegerTransformerAdapter(IntObjectInspector columnType, AbstractTransformer transformer) {
+ this(columnType, transformer, new IntWritable());
+ }
+
+ public IntegerTransformerAdapter(IntObjectInspector columnType, AbstractTransformer transformer, IntWritable writable) {
+ super(transformer);
+
+ this.columnType = columnType;
+ this.writable = writable;
+ }
+
+ @Override
+ public Object getTransformedWritable(DeferredObject object) throws HiveException {
+ Integer value = (Integer)columnType.getPrimitiveJavaObject(object.get());
+
+ if(value != null) {
+ Integer transformedValue = transformer.transform(value);
+
+ if(transformedValue != null) {
+ writable.set(transformedValue);
+
+ return writable;
+ }
+ }
+
+ return null;
+ }
+}
+
比如哈希转换
diff --git a/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDFMaskHash.java b/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDFMaskHash.java
new file mode 100644
index 0000000..c456f43
--- /dev/null
+++ b/ql/src/java/org/apache/hadoop/hive/ql/udf/generic/GenericUDFMaskHash.java
@@ -0,0 +1,77 @@
+/**
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hadoop.hive.ql.udf.generic;
+
+import java.sql.Date;
+
+import org.apache.commons.codec.digest.DigestUtils;
+import org.apache.hadoop.hive.ql.exec.Description;
+import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
+
+
+@Description(name = "mask_hash",
+ value = "returns hash of the given value",
+ extended = "Examples:\n "
+ + " mask_hash(value)\n "
+ + "Arguments:\n "
+ + " value - value to mask. Supported types: STRING, VARCHAR, CHAR"
+ )
+public class GenericUDFMaskHash extends BaseMaskUDF {
+ public static final String UDF_NAME = "mask_hash";
+
+ public GenericUDFMaskHash() {
+ super(new MaskHashTransformer(), UDF_NAME);
+ }
+}
+
+class MaskHashTransformer extends AbstractTransformer {
+ @Override
+ public void init(ObjectInspector[] arguments, int startIdx) {
+ }
+
+ @Override
+ String transform(final String value) {
+ return DigestUtils.md5Hex(value);
+ }
+
+ @Override
+ Byte transform(final Byte value) {
+ return null;
+ }
+
+ @Override
+ Short transform(final Short value) {
+ return null;
+ }
+
+ @Override
+ Integer transform(final Integer value) {
+ return null;
+ }
+
+ @Override
+ Long transform(final Long value) {
+ return null;
+ }
+
+ @Override
+ Date transform(final Date value) {
+ return null;
+ }
+}